
Selenium – это несколько различных проектов с открытым исходным кодом, используемых для автоматизации браузера. Он поддерживает привязки (bindings) для большинства основных языков программирования, включая наш любимый язык: Python.
БЕСПЛАТНО СКАЧАТЬ КНИГИ по Python на русском языке можно у нас в телеграм канале "Python книги на русском"
Selenium API использует протокол WebDriver для управления браузерами, такими как Chrome, Firefox или Safari. Selenium может управлять как локально установленным экземпляром браузера, так и запущенным на удаленной машине по сети.
Изначально (а это уже около 20 лет!) Selenium предназначался для кросс-браузерного сквозного тестирования (приемочных тестов). Однако со временем он стал использоваться в основном как платформа для автоматизации работы с браузерами общего назначения (например, для создания скриншотов), что, конечно же, включает в себя и задачи веб-скрапинга. Редко что может быть лучше во взаимодействии с сайтом, чем настоящий, правильный браузер, не так ли?
Скачивайте книги ТОЛЬКО на русском языке у нас в телеграм канале: PythonBooksRU
Selenium предоставляет широкий спектр способов взаимодействия с сайтами. Например:
- нажатие кнопок
- заполнение форм данными
- прокрутка страницы
- создание скриншотов
- выполнение собственного, пользовательского JavaScript-кода.
Но самый весомый аргумент в пользу Selenium – это его способность работать с сайтами естественным образом, как это делает любой браузер. Особенно ярко это проявляется при работе с одностраничными сайтами, в которых много JavaScript-кода. Если вы будете работать с таким сайтом с помощью традиционной комбинации HTTP-клиента и HTML-парсера, то у вас будет много JavaScript-файлов, но не так много нужных вам данных.
Установка Selenium
Хотя Selenium поддерживает несколько браузеров, для примера мы будем использовать Chrome, поэтому убедитесь, что у вас установлены следующие пакеты:
- Браузер Chrome
- Бинарный драйвер ChromeDriver, соответствующий вашей версии Chrome
- Пакет Selenium Python Binding
Для установки пакета Selenium рекомендуется создать виртуальную среду (например, с помощью virtualenv), а затем установить его туда:
pip install selenium
Быстрый старт
После загрузки Chrome и ChromeDriver и установки пакета Selenium вы можете попробовать запустить браузер:
from selenium import webdriver
DRIVER_PATH = '/path/to/chromedriver'
driver = webdriver.Chrome(executable_path=DRIVER_PATH)
driver.get('https://google.com')
Поскольку мы не настраивали режим headless явно, в этом случае будет отображаться обычное окно Chrome с дополнительным сообщением о том, что Chrome управляется Selenium.

Chrome Headless Mode
Запуск браузера из Selenium, как мы только что сделали, особенно полезен во время разработки. Он позволяет точно наблюдать за тем, что происходит, как ведет себя страница и браузер в контексте вашего кода. Когда все готово, в производственном решении обычно рекомендуется переходить в режим headless.
В этом режиме Selenium запустит Chrome в фоне, без какого-либо визуального вывода или окон. Представьте себе производственный сервер, на котором одновременно запущено несколько экземпляров Chrome со всеми открытыми окнами. Нет смысла тратить ресурсы графического интерфейса без причины.
К счастью, включение “безголового” режима требует всего несколько простых строк.
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
options.headless = True
options.add_argument("--window-size=1920,1200")
driver = webdriver.Chrome(options=options, executable_path=DRIVER_PATH)
Нам остается только инициировать объект Options, установить для его параметра headless значение True и передать настройки в конструктор WebDriver.
Свойства страницы веб-драйвера
На основе нашего примера с режимом без графического интерфейса давайте посетим сайт Nintendo, как настоящие Марио.
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
options.headless = True
options.add_argument("--window-size=1920,1200")
driver = webdriver.Chrome(options=options, executable_path=DRIVER_PATH)
driver.get("https://www.nintendo.com/")
print(driver.page_source)
driver.quit()
При запуске этого скрипта вы получите несколько отладочных сообщений, связанных с браузером, и в конечном итоге HTML-код сайта nintendo.com. Это связано с тем, что наш вызов print обращается к полю page_source драйвера, которое содержит тот самый HTML-документ сайта, который мы запрашивали последним.
Еще два интересных свойства WebDriver:
driver.title– заголовок страницыdriver.current_url– текущий URL (это поле может быть полезно, когда на сайте есть перенаправления и вам нужен конечный URL).
Полный список свойств можно найти в документации WebDriver.
Определение местоположения элементов
Для того чтобы извлечь данные, необходимо знать, где они находятся. Поэтому определение местоположения элементов сайта является одной из ключевых особенностей веб-парсинга. Естественно, Selenium предоставляет такую возможность из коробки (например, в тестовых сценариях необходимо убедиться в наличии/отсутствии определенного элемента на странице).
Существует достаточно много стандартных способов поиска определенного элемента на странице:
- поиск по имени тега
- фильтр по определенному классу или идентификатору элемента HTML
- CSS-селекторы или XPath-выражения для получения элементов
Как обычно, самый простой способ найти элемент – открыть инструменты разработчика Chrome и проинспектировать нужный элемент. Удобное сокращение для этого – выделить нужный элемент мышью и нажать Ctrl + Shift + C или на macOS Cmd + Shift + C вместо того, чтобы каждый раз щелкать правой кнопкой мыши и выбирать Inspect.
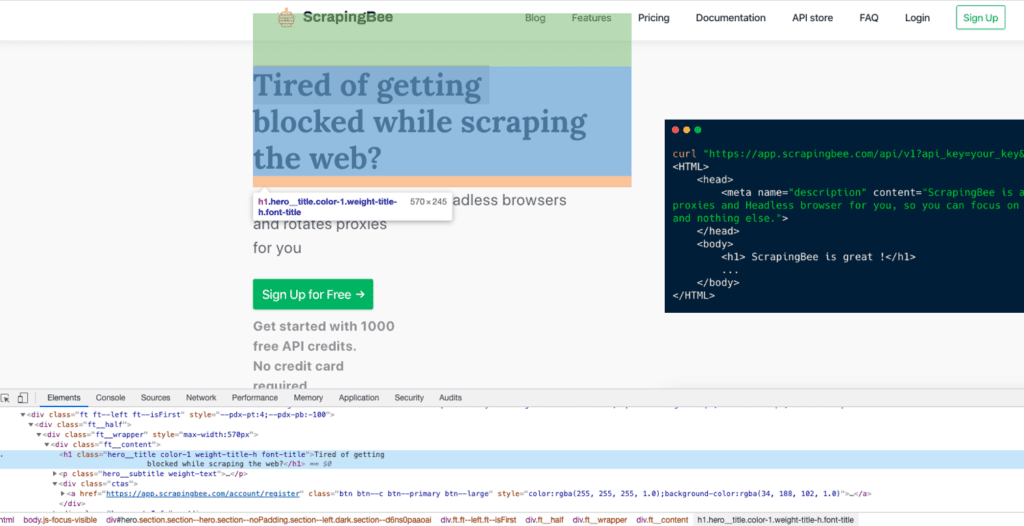
Найдя элемент в дереве DOM, можно определить, каким способом лучше всего программно обратиться к нему. Например, можно щелкнуть правой кнопкой мыши на элементе в инспекторе и скопировать его XPath или CSS-селектор.
Методы find_element и find_elements
WebDriver предоставляет два основных метода для поиска элементов:
find_elementfind_elements
Они довольно похожи, с той лишь разницей, что первый ищет один-единственный элемент, который и возвращает, а второй возвращает список всех найденных элементов.
Оба метода поддерживают восемь различных типов поиска, содержащихся в классе By.
| Тип | Описание | DOM Образец | Пример |
By.ID | Поиск элементов по их HTML ID | <div id="myID"> | find_element(By.ID, "myID") |
By.NAME | Поиск элементов по атрибуту name | <input name="myNAME"> | find_element(By.NAME, "myNAME") |
By.XPATH | Поиск элементов по XPath | <span>My <a>Link</a></span> | find_element(By.XPATH, "//span/a") |
By.LINK_TEXT | Поиск элементов по их текстовому содержанию | <a>My Link</a> | find_element(By.LINK_TEXT, "My Link") |
By.PARTIAL_LINK_TEXT | Поиск элементов на основе совпадения подстроки с их текстовым содержимым | <a>My Link</a> | find_element(By.PARTIAL_LINK_TEXT, "Link") |
By.TAG_NAME | Поиск элементов по имени тега | <h1> | find_element(By.TAG_NAME, "h1") |
By.CLASS_NAME | Поиск элементов по их HTML-классу | <div class="myCLASS"> | find_element(By.CLASSNAME, "myCLASS") |
By.CSS_SELECTOR | Поиск элементов по их CSS-селектору | <span>My <a>Link</a></span> | find_element(By.CSS_SELECTOR, "span > a") |
Полное описание методов можно найти здесь.
find_element
Допустим, у нас есть следующий HTML-документ:
<html>
<head>
... some stuff
</head>
<body>
<h1 class="someclass" id="greatID">Super title</h1>
</body>
</html>
И мы хотим выбрать элемент <h1>. В данном случае следующие пять примеров будут идентичны по возвращаемой информации:
h1 = driver.find_element(By.NAME, 'h1') h1 = driver.find_element(By.CLASS_NAME, 'someclass') h1 = driver.find_element(By.XPATH, '//h1') h1 = driver.find_element(By.XPATH, '/html/body/h1') h1 = driver.find_element(By.ID, 'greatID')
Другим примером может быть выборка всех тегов якорей/ссылки на странице. Поскольку нам нужно несколько элементов, мы используем здесь find_elements (обратите внимание на множественное число)
all_links = driver.find_elements(By.TAG_NAME, 'a')
Некоторые элементы нелегко получить с помощью идентификатора или простого класса, и тогда вам понадобится выражение XPath. Кроме того, у вас может быть несколько элементов с одним и тем же классом, а иногда и ID, хотя последний должен быть уникальным.
XPath – мой любимый способ определения местоположения элементов на веб-странице. Это мощный способ извлечения любого элемента на странице на основе его абсолютной позиции в DOM или относительно другого элемента.
Selenium WebElement
WebElement – это объект Selenium, представляющий элемент HTML.
Существует множество действий, которые можно выполнять с этими объектами, вот наиболее полезные из них:
- Доступ к тексту элемента с помощью свойства
element.text - Клик по элементу с помощью
element.click() - Доступ к атрибутам с помощью
element.get_attribute('class') - Ввести данные в поле для ввода помощью
element.send_keys('mypassword').
Есть и другие интересные методы, например is_displayed(). Он возвращает значение True, если элемент виден пользователю, и может оказаться полезным для предотвращения “Honeypot” защиты (например, намеренно скрытых элементов ввода). Honeypots – это механизмы, используемые владельцами сайтов для борьбы с ботами. Например, HTML-элемент ввода имеет атрибут type=hidden, как показано ниже:
<input type="hidden" id="custId" name="custId" value="">
В таком случае значение (value) должно быть пустым. Если бот посещает страницу и считает, что ему необходимо заполнить значениями все элементы ввода, то он заполнит и скрытое поле ввода. Настоящий пользователь никогда не предоставит значение в это скрытое поле, поскольку оно не отображается браузером.
Это классический пример приманки “Honeypot”.
Полный пример
Приведем полный пример с использованием методов Selenium API, которые мы только что рассмотрели.
Мы собираемся войти в систему Hacker News:
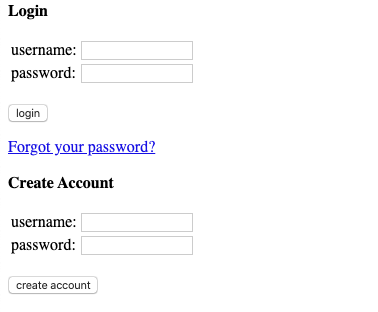
Конечно, аутентификация на Hacker News сама по себе не очень полезна. Однако можно представить себе необходимость создания бота, который будет автоматически публиковать ссылку на вашу последнюю запись в блоге.
Для того чтобы пройти аутентификацию, нам необходимо:
- Перейти на страницу входа в систему с помощью
driver.get() - Выбрать поле ввода имени пользователя с помощью
driver.find_elementи вызватьelement.send_keys()для отправки текста в это поле. - Проделать те же действия с полем ввода пароля
- Выбрать кнопку входа в систему (конечно же, с помощью элемента
find_element) и нажать ее с помощьюelement.click().
Все должно быть просто, верно? Давайте посмотрим на код:
driver.get("https://news.ycombinator.com/login")
login = driver.find_element_by_xpath("//input").send_keys(USERNAME)
password = driver.find_element_by_xpath("//input[@type='password']").send_keys(PASSWORD)
submit = driver.find_element_by_xpath("//input[@value='login']").click()
Легко, правда? Но здесь не хватает одного важного момента. Как узнать, вошли ли мы в систему?
Мы можем попробовать несколько способов:
- Проверить наличие сообщения об ошибке (например, “Неверный пароль”).
- Проверить наличие на странице элемента, который отображается только после входа в систему.
Итак, мы проверим кнопку выхода из системы. Она имеет идентификатор logout.
Мы не можем просто проверить, является ли элемент значением None, поскольку find_element вызывает исключение, если элемент не найден в DOM. Поэтому мы должны использовать блок try/except и перехватить исключение NoSuchElementException:
from selenium.common.exceptions import NoSuchElementException
try:
logout_button = driver.find_element_by_id("logout")
print('Successfully logged in')
except NoSuchElementException:
print('Incorrect login/password')
Великолепно! Все работает.
Примечание редакции: об использовании try/except читайте в статье “Чем полезна обработка ошибок при помощи try-except”.
Создание скриншотов
Прелесть браузерных подходов, таких как Selenium, заключается не только в том, что мы получаем данные и дерево DOM, но и в том, что, будучи браузером, он также правильно отображает всю страницу. Это, конечно, позволяет делать скриншоты, и в Selenium это реализовано.
driver.save_screenshot('screenshot.png')
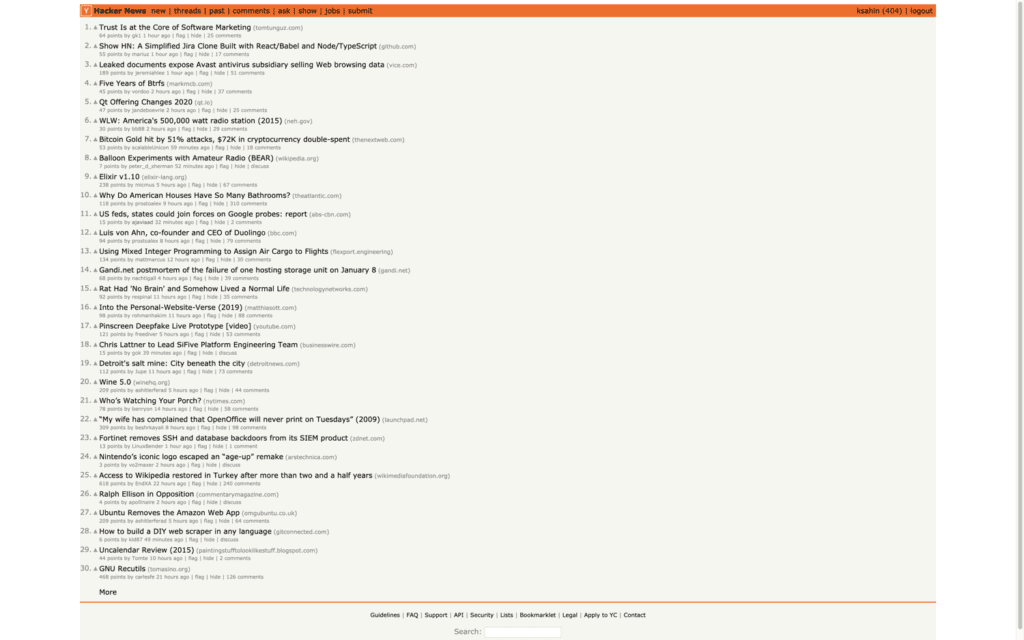
Одна строчка – и у нас есть скриншот нашей страницы. Ну разве это не здорово?
Обратите внимание, что при создании скриншота с помощью Selenium некоторые вещи могут пойти не так, как надо, или потребовать доработки. Во-первых, необходимо убедиться, что размер окна установлен правильно. Во-вторых, нужно проверить, все ли асинхронные HTTP-вызовы, выполняемые фронтенд-кодом JavaScript, завершены, и полностью ли отрисована страница.
В нашем случае с Hacker News все просто, и нам не нужно беспокоиться об этих проблемах.
Ожидание появления элемента
Работа с сайтом, использующим большое количество JavaScript для отображения содержимого, может оказаться непростой задачей. В настоящее время все больше сайтов используют такие фреймворки, как Angular, React и Vue.js, для отрисовки контента. Работа с этими фреймворками сложна тем, что они не просто предоставляют HTML-код, а содержат довольно сложный набор JavaScript-кода, который изменяет дерево DOM “на лету” и отправляет множество информации асинхронно в фоновом режиме через AJAX.
Это означает, что мы не можем просто послать запрос и сразу же получить данные, а должны подождать, пока JavaScript завершит свою работу. Обычно это можно сделать двумя способами:
- Использовать
time.sleep()перед тем, как сделать снимок экрана. - Использовать объект
WebDriverWait.
Если вы используете time.sleep(), то вам придется использовать наиболее разумную задержку для вашего случая. Проблема в том, что вы либо ждете слишком долго, либо недостаточно долго, и ни то, ни другое не является идеальным вариантом. Кроме того, сайт может загружаться медленнее на вашем домашнем ISP-соединении, чем когда ваш код работает в рабочей среде она сервере.
При использовании WebDriverWait это не нужно принимать во внимание. Он будет ждать столько, сколько необходимо, пока не появится нужный элемент (или пока не наступит таймаут).
try:
element = WebDriverWait(driver, 5).until(
EC.presence_of_element_located((By.ID, "mySuperId"))
)
finally:
driver.quit()
При этом будет ожидаться появление элемента с HTML-идентификатором mySuperId или истечение пятисекундного тайм-аута. Существует множество других типов исключенных условий:
alert_is_presentelement_to_be_clickabletext_to_be_present_in_elementvisibility_of
Полный список Waits и их ожидаемых условий можно, конечно, найти в документации Selenium.
Но, имея в своем распоряжении полноценный браузерный движок, мы можем не только работать с JavaScript-кодом, выполняемым сайтом, но и запускать свой собственный, пользовательский JavaScript. Давайте проверим это.
Выполнение JavaScript
Как и в случае со скриншотами, мы можем в полной мере использовать JavaScript-движок нашего браузера. Это означает, что мы можем внедрить и выполнить произвольный код в контексте сайта. Хотите сделать скриншот фрагмента, расположенного немного ниже по странице? Легко: window.scrollBy() и execute_script() помогут вам в этом.
javaScript = "window.scrollBy(0, 1000);" driver.execute_script(javaScript)
Или вы хотите выделить все ссылки рамкой? Это проще простого.
javaScript = "document.querySelectorAll('a').forEach(e => e.style.border='red 2px solid')"
driver.execute_script(javaScript)
Дополнительным преимуществом функции execute_script() является то, что она возвращает результат выполнения переданного выражения. Например, следующий код передаст заголовок нашего документа прямо в нашу переменную title:
title = driver.execute_script('return document.title')
Неплохо, не правда ли?
Так как метод execute_script() может возвращать значение, он является синхронным по своей природе. Если вам не нужно ждать значения, то, конечно же, можно использовать его асинхронный аналог execute_async_script().
Использование прокси в Selenium Wire
К сожалению, функционал прокси в Selenium достаточно прост. Например, там нет возможности обрабатывать аутентификацию через прокси из коробки.
Для решения этой проблемы можно использовать Selenium Wire. Этот пакет расширяет связку Selenium и предоставляет доступ ко всем базовым запросам, выполняемым браузером. Если вам необходимо использовать Selenium с прокси-сервером с аутентификацией, то вам нужен именно этот пакет.
pip install selenium-wire
Этот фрагмент кода показывает, как быстро использовать headless-браузер вместе с прокси-сервером.
from seleniumwire import webdriver
proxy_username = "USER_NAME"
proxy_password = "PASSWORD"
proxy_url = "http://proxy.scrapingbee.com"
proxy_port = 8886
options = {
"proxy": {
"http": f"http://{proxy_username}:{proxy_password}@{proxy_url}:{proxy_port}",
"verify_ssl": False,
},
}
URL = "https://httpbin.org/headers?json"
driver = webdriver.Chrome(
executable_path="YOUR-CHROME-EXECUTABLE-PATH",
seleniumwire_options=options,
)
driver.get(URL)
Блокировка изображений и JavaScript
Наличие под рукой всего набора стандартных функций браузера действительно выводит парсинг на новый уровень. Мы можем получить полностью отрисованные страницы, что позволяет делать скриншоты, а JavaScript сайта правильно выполняется в нужном контексте.
Тем не менее, иногда все эти возможности нам не нужны. Например, если мы не делаем скриншотов, то нет смысла загружать все изображения. К счастью, Selenium и WebDriver позаботились об этом.
Помните класс Options? Он также принимает объект preferences, в котором можно включать и выключать функции по отдельности. Например, если мы хотим отключить загрузку изображений и выполнение JavaScript-кода, мы используем следующие опции:
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
### This blocks images and javascript requests
chrome_prefs = {
"profile.default_content_setting_values": {
"images": 2,
"javascript": 2,
}
}
chrome_options.experimental_options["prefs"] = chrome_prefs
###
driver = webdriver.Chrome(
executable_path="YOUR-CHROME-EXECUTABLE-PATH",
chrome_options=chrome_options,
)
driver.get(URL)
Заключение
Надеюсь, вам понравилась эта статья! Теперь вы должны понимать, как работает Selenium API в Python.
Selenium также является отличным инструментом для автоматизации практически любых действий в Интернете.
Если вы выполняете повторяющиеся задачи, например, заполняете формы или проверяете информацию на сайте где нет API, возможно, стоит автоматизировать эти действия с помощью Selenium. Только не забывайте об этом комиксе xkcd:

Перевод статьи «Web Scraping Using Selenium And Python».
Пингбэк: Парсинг данных Google Maps с помощью Python
Пингбэк: Как нажать на кнопку с помощью Selenium
Пингбэк: Фреймворки для тестирования на Selenium
Пингбэк: Использование прокси в Selenium
Пингбэк: Готовые скрипты Python для автоматизации работы