
Благодаря своей обширной базе данных местоположений, организаций, отзывов и многого другого, Google Maps часто используется для извлечения данных. Однако ручное извлечение этих данных может быть утомительной и затратной по времени задачей. В этой статье мы рассмотрим, как при помощи Python реализовать парсинг данных с Google Maps, что позволит вам эффективно и оперативно собирать необходимую информацию.
Итак, если вы специалист по анализу данных, профессионал в бизнесе или просто любопытный человек, присоединяйтесь к нам, чтобы узнать, как использовать Python для поиска адресов магазинов и другой информации на Google Maps.
Скачивайте книги ТОЛЬКО на русском языке у нас в телеграм канале: PythonBooksRU
Python является удобным инструментом для сбора данных, в нем имеется множество библиотек, специально разработанных для этой цели. Что касается сбора данных с таких сайтов, как Google Maps, то Python предоставляет целый ряд библиотек и фреймворков, которые могут помочь в этом процессе. Выбор подходящей библиотеки является важным шагом в создании парсера и зависит от требований проекта и навыков программирования.
Установка необходимых библиотек
В этой статье рассматриваются три варианта парсиинга и обсуждаются следующие Python-библиотеки для получения информации с Google Maps:
- Парсинг с использованием библиотек Requests и BeautifulSoup. Этот вариант имеет свои плюсы и минусы. Это простой подход, подходящий для новичков и не требующий особых навыков. Однако он не может эмулировать поведение пользователя и не обрабатывает JavaScript-рендеринг.
- Скрапинг с использованием безголового браузера (библиотека Selenium). Этот вариант требует более развитых навыков программирования и дополнительной загрузки веб-драйвера. Он позволяет взаимодействовать с веб-страницей так, как это делал бы пользователь, в том числе обрабатывать содержимое с JavaScript-рендерингом.
- Парсинг с использованием библиотеки Google Maps API. Использование специально разработанной библиотеки для скрапинга Google Maps является хорошим решением и наиболее удобным вариантом. Он позволяет решить проблемы, с которыми сталкивались предыдущие два метода, например, обойти проблемы с CAPTCHA и избежать необходимости использования прокси-серверов. Кроме того, можно использовать бескодовый парсер данных Google Maps, не требующий навыков программирования.
Для установки всех необходимых библиотек откройте командную строку и выполните следующие команды:
pip install beautifulsoup4 pip install selenium pip install sc-google-maps-api
Библиотека Requests, которую мы также будем использовать, предустановлена. Для использования безголового браузера нам также необходимо установить веб-драйвер.
Выбор веб-драйвера зависит от того, какой браузер вы хотите автоматизировать. Например, если требуется автоматизировать Chrome, то необходим драйвер Chrome. Убедитесь, что версия загружаемого драйвера соответствует версии установленного браузера.
Чтобы установить WebDriver, посетите официальный сайт WebDriver и загрузите его. Мы рекомендуем сохранить его в легкодоступном месте, например на диске C://. Избегайте использования сложных путей, так как в дальнейшем нам придется прописывать их в сценарии.
Исследование веб-страниц Google Maps
Прежде чем приступить к сбору данных, необходимо понять, где и в каком виде они находятся. Для этого зайдем на Google Maps и попробуем найти любое местоположение. После этого откроем DevTools (F12, или щелкните правой кнопкой мыши на экране и выберите пункт Inspect).
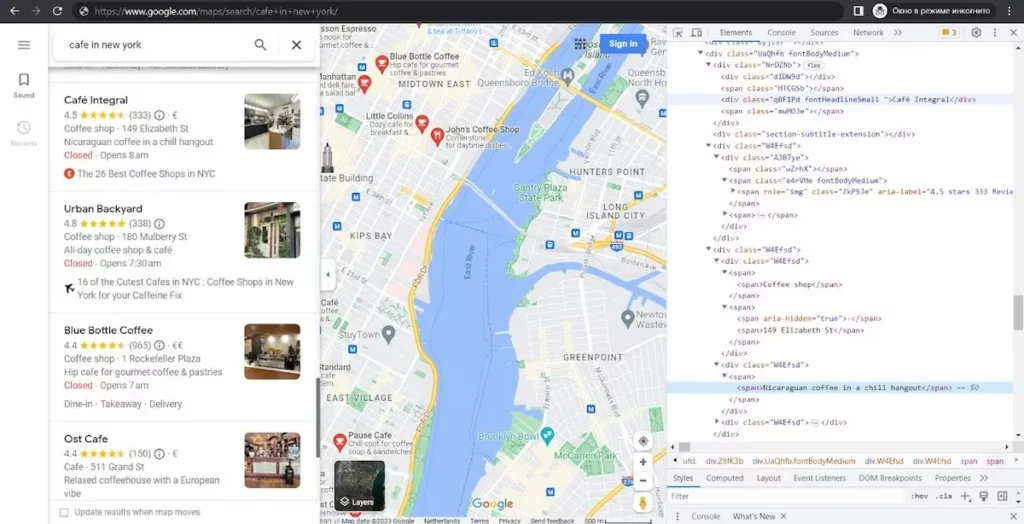
Если внимательно посмотреть на эту страницу, то можно заметить, что все заголовки страниц и их описания имеют класс с уникальным именем, который каждый раз генерируется заново. Однако каждый элемент также имеет класс article, что облегчает получение данных. Кроме того, как мы видим, заголовки имеют класс fontHeadlineSmall, а описания хранятся в теге span.
Парсинг данных с помощью Python
Google Maps API
Для начала рассмотрим пример использования Google Maps API, поскольку он требует минимальных навыков программирования. Сначала зарегистрируйтесь на сайте scrape-it.cloud, чтобы получить ключ API и несколько бесплатных кредитов. Для получения данных можно использовать этот скрипт:
from sc_google_maps_api import ScrapeitCloudClient
client = ScrapeitCloudClient(api_key='INSERT_YOUR_API_KEY_HERE')
response = client.scrape(
params={
"keyword": "cafe in new york",
"country": "US",
"domain": "com"
}
)
print(response.text)
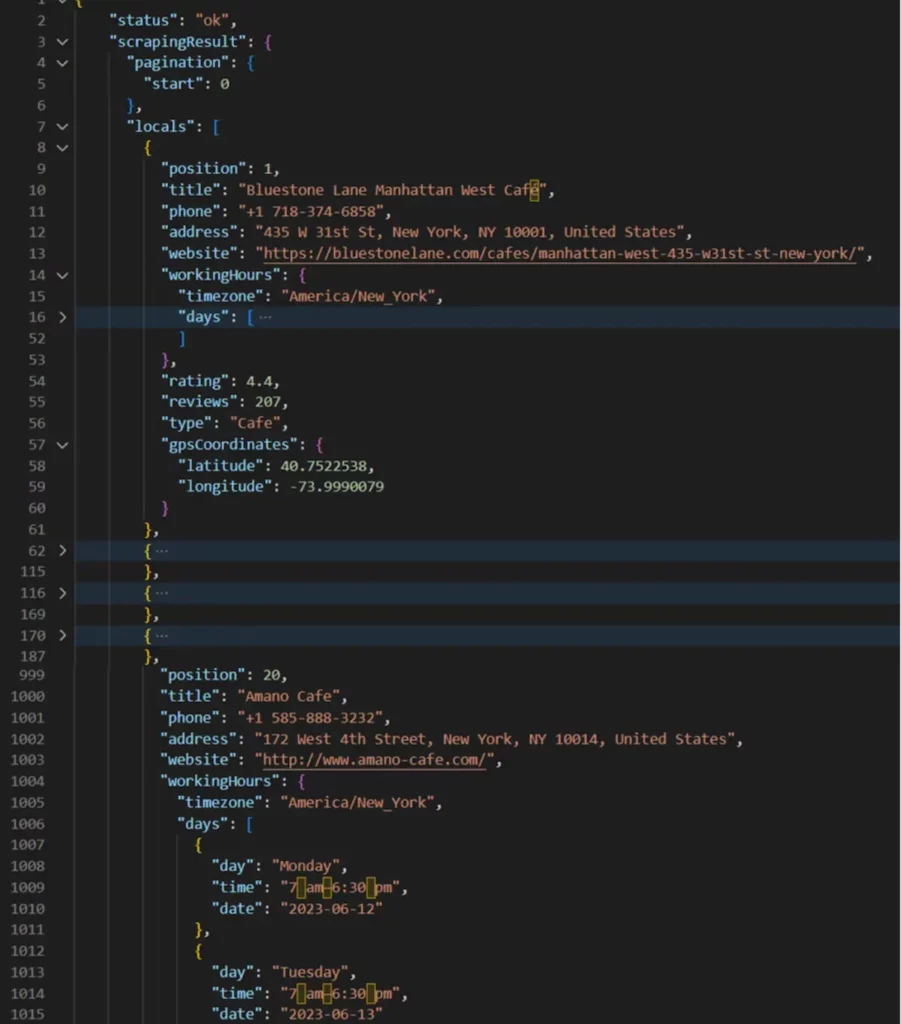
Сохранив и выполнив этот скрипт, вы получите исчерпывающие данные о первых 20 позициях, уже структурированные в формате JSON:
Requests и BeautifulSoup
Теперь усложним задачу и попробуем получить данные с помощью библиотек Requests и BeautifulSoup. Для этого мы импортируем необходимые библиотеки, отправим запрос на страницу и разберем полученный ответ:
import requests
from bs4 import BeautifulSoup
header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'}
data = requests.get('https://www.google.com/maps/search/cafe+in+new+york/', headers=header)
soup = BeautifulSoup(data.text, "html.parser")
titles = soup.find_all('div', {'class':'fontHeadlineSmall'})
descriptions = soup.find_all('div', {'class':'fontBodyMedium'})
print(titles)
print(descriptions)
Однако никаких данных мы не получим, поскольку эти библиотеки прекрасно работают со статическими веб-страницами, но не подходят для сбора данных с динамически генерируемых страниц, таких как Google Maps.
Selenium
И, наконец, еще один вариант – Selenium, который позволяет моделировать поведение пользователя и, соответственно, получать динамически генерируемые данные. То есть мы можем парсить не только статические данные, но и динамический контент, который генерируется или изменяется в результате взаимодействия со страницей.
Примечание редакции: о применении Selenium читайте в статье “Парсинг при помощи Python и Selenium”.
Импортируем необходимые библиотеки и зададим путь к веб-драйверу:
from selenium import webdriver from selenium.webdriver.common.by import By DRIVER_PATH = 'C:\chromedriver.exe' driver = webdriver.Chrome(executable_path=DRIVER_PATH)
Далее мы укажем ссылку, по которой нужно перейти. Важно отметить, что все ссылки в Google Maps имеют стандартную структуру. Это позволит нам в будущем усовершенствовать код, автоматически генерируя ссылки для поиска нужной нам информации.
driver.get('https://www.google.com/maps/search/cafe+in+new+york/')
Теперь создадим переменную для хранения данных в парах заголовок-описание.
results =[]
Далее необходимо получить все элементы. Как мы помним из структуры, все элементы имеют атрибут role="article".
elems = driver.find_elements(By.XPATH, "//div[@role='article']")
Теперь осталось выполнить итерацию по каждому элементу последовательности и собрать нужные данные, которые необходимо сохранить в переменной results:
for elem in elems:
title = elem.find_element(By.CSS_SELECTOR, "div.fontHeadlineSmall")
description = elem.find_element(By.CSS_SELECTOR, "div.fontBodyMedium")
results.append(str(title.text)+';'+str(description.text))
Наконец, не забудем закрыть драйвер, а для удобства выведем данные на экран:
driver.close() print(results)
При выполнении этого сценария браузер откроется, перейдет на страницу Google Maps и выполнит все необходимые действия и сбор данных. По завершении мы получим следующие данные:
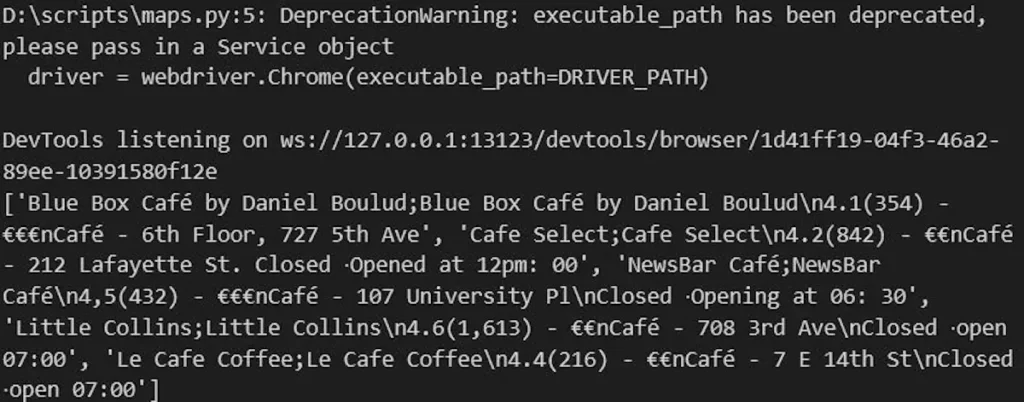
Как видно, мы получаем данные только для 5 элементов, что значительно меньше, чем при использовании API. Добавление в сценарий функций прокрутки и задержек поможет загружать новые данные.
Хранение полученных данных
Ранее мы отображали полученные данные в консоли. Однако, чтобы сделать пример более полным, давайте сохраним данные, полученные в последнем примере, в файл.
Для сохранения данных в файл мы можем использовать возможности Python по работе с файлами. Вот пример того, как можно модифицировать скрипт для записи данных в файл:
with open("maps.csv", "w", encoding="utf-8") as f:
f.write("Title; Description\n")
for result in results:
f.write(str(result) + "\n")
Этот код создает или перезаписывает файл maps.csv, записывает в него имена колонок “Title” и “Description”. Затем мы построчно перебираем результаты, хранящиеся в переменной results, и добавляем их в файл.
На этом этапе, как правило, речь идет о сохранении данных и их очистке. Например, это может быть удаление лишних символов, исправление ошибок в данных или удаление пустых строк. Этот этап очень важен, поскольку необработанные данные могут оказаться непригодными для дальнейшего анализа.
Кроме того, важно отметить, что очистка данных позволяет повысить их качество и обеспечить точность и надежность анализа. Устранив несоответствия и убрав ненужную информацию, мы можем получить нужную нам структурированную информацию в удобном формате.
Заключение
Язык Python предоставляет мощные инструменты и библиотеки для эффективного извлечения данных из Google Maps. Парсинг данных с Google Maps позволяет получить информацию о местных предприятиях, проанализировать отзывы и оценки клиентов, собрать контактную информацию и многое другое. Независимо от того, являетесь ли вы владельцем бизнеса, которому нужна конкурентная разведка, или энтузиастом, ищущим интересные закономерности и тенденции, парсинг данных с Google Maps может дать вам огромное количество информации.
В данной статье мы продемонстрировали примеры извлечения данных из Google Maps с помощью языка Python. Мы использовали Google Maps API для простого и быстрого получения структурированных данных. Мы также попробовали осуществить парсинг данных с Google Maps с помощью библиотек Requests и BeautifulSoup, хотя они не подходят для динамически генерируемых страниц, таких как Google Maps. Наконец, мы использовали Selenium с безголовым браузером для имитации поведения пользователя и получения динамического содержимого страницы.
Перевод статьи «How to Scrape Data from Google Maps Using Python».