
Работа с кодировками символов в Python или любом другом языке иногда может показаться болезненной. В таких местах, как Stack Overflow, есть тысячи вопросов, возникающих из-за путаницы с исключениями типа UnicodeDecodeError и UnicodeEncodeError. Это руководство призвано рассеять туман неведения и показать, что работа с текстом и двоичными данными в Python может быть очень простой. Поддержка Юникод в Python сильная и надежная, но для ее освоения требуется некоторое время.
Оглавление
- Что такое кодировка символов?
- Другие системы исчисления
- Юникод
- Встроенные функции Python
- Строковые литералы Python
- Другие кодировки, доступные в Python
- Вы знаете, что говорят о предположениях…
- Дополнительно: unicodedata
- Подведение итогов
Этот учебник отличается тем, что теория не привязана к языку, хотя дальнейшие примеры и будут приведены на языке Python. По итогу вы получите теоретические знания по данной теме, а затем погрузитесь в примеры на Python.
К концу этого учебного курса вы:
- Получите представление о кодировках и системах счисления
- Поймете роль кодировки в str и bytes в Python.
- Узнаете о поддержке систем исчисления в Python через различные формы литералов типа int
- Познакомитесь со встроенными функциями Python, связанными с кодировкой символов и системами счисления.
Кодировка символов и системы счисления настолько тесно связаны, что их необходимо рассматривать в одном руководстве, иначе изложение будет неполным.
Примечание. Эта статья ориентирована на Python 3. В частности, все примеры кода в этом учебнике были сгенерированы из оболочки CPython 3.7.2, хотя все младшие версии Python 3 должны вести себя (в основном) одинаково при работе с текстом.
Что такое кодировка символов?
Существуют десятки, если не сотни кодировок символов. Лучший способ разобраться, что это такое, – рассмотреть одну из самых простых кодировок символов – ASCII.
Независимо от того, являетесь ли вы самоучкой или имеете формальное образование в области компьютерных наук, скорее всего, вы видели таблицу ASCII. Это хороший старт для начала изучения кодирования символов, поскольку это небольшая и содержательная кодировка.
Она включает в себя следующее:
- Строчные английские буквы от a до z.
- Прописные английские буквы от A до Z.
- Некоторые знаки препинания и символы, например, “$” и “!”.
- Пробельные символы: фактический пробел (
" "), а также символ новой строки, возврата каретки, горизонтальной табуляции, вертикальной табуляции и несколько других. - Некоторые непечатаемые символы. Это символы, такие как backspace,
"\b", которые нельзя напечатать буквально, как , например,"A".
Каково же более формальное определение кодировки символов?
На самом высоком уровне это способ перевода символов (таких как буквы, знаки препинания, символы, пробелы и управляющие символы) в целые числа и, в конечном итоге, в биты. Каждый символ может быть закодирован в уникальную последовательность битов. Не волнуйтесь, если вы не очень хорошо представляете себе понятие “биты”, потому что мы скоро к ним перейдем.
Приведенные ниже категории представляют собой группы символов. Каждому отдельному символу соответствует код, который можно рассматривать как просто целое число. Внутри таблицы ASCII символы разделены на диапазоны:
| 0 – 31 | Управляющие/непечатаемые символы |
| 32 – 64 | Знаки препинания, символы, числа и пробел |
| 65 – 90 | Прописные буквы английского алфавита |
| 91 – 96 | Дополнительные графемы, такие как [ и \ |
| 97 – 122 | Строчные буквы английского алфавита |
| 123 – 126 | Дополнительные графемы, такие как { и | |
| 127 | Управляющий/непечатаемый символ (DEL) |
Вся таблица ASCII содержит 128 символов. Эта таблица отражает полный набор символов, который допускает ASCII. Если вы не видите здесь какого-либо символа, значит, вы просто не можете выразить его в виде печатного текста в соответствии со схемой кодирования ASCII.
Модуль string в Python
Модуль string в Python – это удобный универсальный модуль для работы со строковыми константами, входящими в набор символов ASCII.
Вот ядро модуля во всей его красе:
# From lib/python3.7/string.py
whitespace = ' \t\n\r\v\f'
ascii_lowercase = 'abcdefghijklmnopqrstuvwxyz'
ascii_uppercase = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
ascii_letters = ascii_lowercase + ascii_uppercase
digits = '0123456789'
hexdigits = digits + 'abcdef' + 'ABCDEF'
octdigits = '01234567'
punctuation = r"""!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~"""
printable = digits + ascii_letters + punctuation + whitespace
Большинство этих констант должны быть понятны по имени идентификатора. Мы скоро рассмотрим, что такое hexdigits и octdigits.
Вы можете использовать эти константы для манипуляций со строками:
>>> import string >>> s = "What's wrong with ASCII?!?!?" >>> s.rstrip(string.punctuation) 'What's wrong with ASCII'
Примечание. string.printable включает в себя все пробельные символы string.whitespace. Это немного расходится с другим методом проверки того, считается ли символ печатным, а именно str.isprintable(), который скажет вам, что ни один из {‘\v’, ‘\n’, ‘\r’, ‘\f’, ‘\t’} не считается печатным.
Это тонкое различие обусловлено определением: str.isprintable() считает что-то печатаемым, если “все его символы могут быть напечатаны в repr()“.
Небольшой ликбез: биты и байты
Сейчас самое время кратко рассказать о бите – самой фундаментальной единице информации, которую знает компьютер.
Бит – это сигнал, который имеет только два возможных состояния. Существуют различные способы символического представления бита, которые означают одно и то же:
- 0 или 1
- “да” или “нет”
- True или False
- “включено” или “выключено”
В таблице ASCII из предыдущего раздела используется то, что мы с вами называем просто числами (от 0 до 127), то это десятичные числа (числа по снованию 10).
Каждое из этих чисел можно также выразить последовательностью битов в двоичном формате (основание 2). Вот двоичные версии чисел от 0 до 10 в десятичной системе счисления:
| Десятичный формат | Бинарный формат (компактный) | Бинарный формат (расширенный) |
|---|---|---|
| 0 | 0 | 00000000 |
| 1 | 1 | 00000001 |
| 2 | 10 | 00000010 |
| 3 | 11 | 00000011 |
| 4 | 100 | 00000100 |
| 5 | 101 | 00000101 |
| 6 | 110 | 00000110 |
| 7 | 111 | 00000111 |
| 8 | 1000 | 00001000 |
| 9 | 1001 | 00001001 |
| 10 | 1010 | 00001010 |
Обратите внимание, что по мере увеличения десятичного числа n вам требуется все больше значащих битов для представления набора символов до этого числа включительно.
Вот удобный способ представления строк ASCII в виде последовательностей битов в Python. Каждый символ из строки ASCII псевдокодируется в 8 бит, с пробелами между 8-битными последовательностями, каждая из которых представляет один символ:
>>> def make_bitseq(s: str) -> str:
... if not s.isascii():
... raise ValueError("ASCII only allowed")
... return " ".join(f"{ord(i):08b}" for i in s)
>>> make_bitseq("bits")
'01100010 01101001 01110100 01110011'
>>> make_bitseq("CAPS")
'01000011 01000001 01010000 01010011'
>>> make_bitseq("$25.43")
'00100100 00110010 00110101 00101110 00110100 00110011'
>>> make_bitseq("~5")
'01111110 00110101'
В f-строке f"{ord(i):08b}" используется мини-язык спецификации формата Python, который представляет собой способ задания формата вывода для переменных при формировании строк:
- Левая часть до двоеточия,
ord(i), является фактическим объектом, значение которого будет отформатировано и вставлено в вывод. Использование функции Pythonord()дает вам кодовый символ в десятичной системе для одного символа str. - Правая часть после двоеточия – это спецификатор формата. Число 08 означает ширину 8 с заполнением нулями, а буква
bуказывает на вывод результата в двоичной системе счисления.
Этот трюк в основном просто для развлечения, и он провалится для любого символа, которого нет в таблице ASCII. Позже мы обсудим, как другие кодировки решают эту проблему.
Нам нужно больше битов!
Существует критически важная формула, связанная с определением бита. При количестве битов n, число различных возможных значений, которые могут быть представлены в n битах, равно 2n:
def n_possible_values(nbits: int) -> int:
return 2 ** nbits
Вот что это значит:
- 1 бит позволит вам выразить 21 == 2 возможных значения.
- 8 битов позволят вам выразить 28 == 256 возможных значений.
- 64 бита позволят вам выразить 264 == 18 446 744 073 709 551 616 возможных значений.
Из этой формулы вытекает следующее. Если дан диапазон различных возможных значений, как найти количество бит n, необходимое для полного представления этого диапазона? Нам нужно решить уравнение 2n = x (где x уже известен).
Вот что из этого получается:
>>> from math import ceil, log >>> def n_bits_required(nvalues: int) -> int: ... return ceil(log(nvalues) / log(2)) >>> n_bits_required(256) 8
Все это служит доказательством одной концепции: ASCII, строго говоря, является 7-битным кодом. Таблица ASCII, которую вы видели выше, содержит 128 кодовых символов, от 0 до 127 включительно. Для этого требуется 7 бит:
>>> n_bits_required(128) # 0 through 127 7 >>> n_possible_values(7) 128
Проблема в том, что современные компьютеры почти ничего не хранят в 7-битных слотах. Они хранят информацию в единицах по 8 бит, называемых байтами.
Примечание. В этой статье я предполагаю, что байт обозначает 8 бит, как это принято с 1960-х годов, а не какую-то другую единицу хранения. Вы можете называть это октетом, если вам так удобнее.
Это означает, что пространство для хранения, используемое ASCII, наполовину пусто. Если непонятно, почему это так, вспомните таблицу перевода десятичных чисел в двоичные, приведенную выше. Вы можете выразить числа 0 и 1 с помощью всего 1 бита или использовать 8 бит, чтобы выразить их как 00000000 и 00000001 соответственно.
Числа от 0 до 3 можно выразить всего 2 битами, или от 00 до 11, или использовать 8 бит, чтобы выразить их как 00000000, 00000001, 00000010 и 00000011 соответственно. Наивысшая кодовая точка ASCII, 127, требует всего 7 значащих битов.
Зная это, вы можете видеть, что make_bitseq() преобразует строки ASCII в строковое представление байтов, где каждый символ занимает один байт:
>>> make_bitseq("bits")
'01100010 01101001 01110100 01110011'
Недоиспользование ASCII 8-битных байтов, предлагаемых современными компьютерами, привело к появлению целого семейства конфликтующих неформализованных кодировок, каждая из которых определяла дополнительные символы, которые должны были использоваться с оставшимися 128 доступными кодовыми точками, допустимыми в 8-битной схеме кодирования символов.
Эти различные кодировки не только противоречили друг другу. Ни одна из них сама по себе не могла покрыть все символы мира, несмотря на то, что в них использовался один дополнительный бит.
С течением времени одна мегасхема кодирования символов набрала популярность и стала использоваться практически везде. Однако прежде чем мы перейдем к этому, давайте поговорим о системах исчисления, которые являются фундаментальной основой схем кодирования символов.
Другие системы счисления
Из раздела, посвященного ASCII, вы узнали, что каждый символ соответствует целому числу в диапазоне от 0 до 127.
Этот диапазон целых чисел выражается в десятичной системе счисления (основание 10). Это способ, которым мы, ты, и остальные люди привыкли считать просто потому, что у нас есть 10 пальцев.
Однако существуют и другие системы счисления, которые особенно распространены в исходном коде CPython. Все эти системы различными способами представляют одни и те же числа.
Если я спрошу вас, какое число обозначает строка “11”, вы, скорее всего, посмотрите на меня странно, и ответите, что она обозначает одиннадцать.
Однако это строковое представление может выражать различные числа в разных системах счисления. Помимо десятичной, к распространенным системам счисления относятся:
- двоичная (основание 2)
- восьмеричная (основание 8)
- шестнадцатеричная (основание 16).
Но что значит сказать, что в определенной системе счисления числа представлены с основанием N?
Вот лучший из известных мне способов сформулировать, что это значит: это количество пальцев, на которых вы считаете в данной системе.
Если вы хотите получить более полное, но все же мягкое введение в системы счисления, “Код” Чарльза Петцольда – невероятно крутая книга, в которой подробно рассматриваются основы компьютерного кода.
Один из способов продемонстрировать, как разные системы счисления интерпретируют одно и то же, – это конструктор int() в Python. Если вы передадите в int() строку str, Python по умолчанию будет считать, что строка выражает число по основанию 10, если вы не скажете ему обратное:
>>> int('11')
11
>>> int('11', base=10) # 10 is already default
11
>>> int('11', base=2) # Binary
3
>>> int('11', base=8) # Octal
9
>>> int('11', base=16) # Hex
17
Существует более распространенный способ сообщить Python, что ваше целое число набрано с основанием, отличным от 10. Python принимает буквенные формы каждой из трех альтернативных систем счисления, приведенных выше:
| Тип литерала | Префикс | Пример |
|---|---|---|
| n/a | n/a | 11 |
| Binary literal | 0b или 0B | 0b11 |
| Octal literal | 0o или 0O | 0o11 |
| Hex literal | 0x или 0X | 0x11 |
Все они являются подформами целочисленных литералов. Вы можете видеть, что они дают те же результаты, что и вызовы int() со значениями основания не по умолчанию. Для Python они все просто int:
>>> 11 11 >>> 0b11 # Binary literal 3 >>> 0o11 # Octal literal 9 >>> 0x11 # Hex literal 17
Вот как можно напечатать двоичный, восьмеричный и шестнадцатеричный эквиваленты десятичных чисел от 0 до 20. Любой из этих вариантов вполне допустим в оболочке интерпретатора Python или в исходном коде, и все они имеют тип int.
| Decimal | Binary | Octal | Hex |
0 | 0b0 | 0o0 | 0x0 |
| 1 | 0b1 | 0o1 | 0x1 |
| 2 | 0b10 | 0o2 | 0x2 |
| 3 | 0b11 | 0o3 | 0x3 |
| 4 | 0b100 | 0o4 | 0x4 |
| 5 | 0b101 | 0o5 | 0x5 |
| 6 | 0b110 | 0o6 | 0x6 |
| 7 | 0b111 | 0o7 | 0x7 |
| 8 | 0b1000 | 0o10 | 0x8 |
| 9 | 0b1001 | 0o11 | 0x9 |
| 10 | 0b1010 | 0o12 | 0xa |
| 11 | 0b1011 | 0o13 | 0xb |
| 12 | 0b1100 | 0o14 | 0xc |
| 13 | 0b1101 | 0o15 | 0xd |
| 14 | 0b1110 | 0o16 | 0xe |
| 15 | 0b1111 | 0o17 | 0xf |
| 16 | 0b10000 | 0o20 | 0x10 |
| 17 | 0b10001 | 0o21 | 0x11 |
| 18 | 0b10010 | 0o22 | 0x12 |
| 19 | 0b10011 | 0o23 | 0x13 |
| 20 | 0b10100 | 0o24 | 0x14 |
Целочисленные литералы в CPython
Удивительно, насколько распространены эти выражения в стандартной библиотеке Python. Если вы хотите убедиться в этом, перейдите в каталог lib/python3.7/ и проверьте использование шестнадцатеричных литералов:
$ grep -nri --include "*\.py" -e "\b0x" lib/python3.7
Это должно работать на любой системе Unix, где есть grep. Вы можете использовать "\b0o" для поиска восьмеричных литералов или "\b0b" для поиска двоичных.
Зачем использовать эти альтернативные синтаксисы литералов int? Если коротко, то затем, что 2, 8 и 16 – это степени 2, а 10 – нет. Эти три альтернативные системы счисления иногда дают возможность выразить значения в удобной для компьютера манере. Например, число 65536 или 216 – это просто 10000 в шестнадцатеричной системе счисления, или 0x10000 как шестнадцатеричный литерал Python.
Юникод
Как вы видели, проблема с ASCII заключается в том, что набор символов недостаточно велик, чтобы вместить в себя все языки, диалекты, символы и глифы мира. (Он даже недостаточно велик для одного только английского языка).
Юникод (англ. Unicode) в основном служит той же цели, что и ASCII, но охватывает намного больший набор символов.
Существует несколько кодировок, которые появились хронологически между ASCII и Юникод, но пока они не стоят упоминания, потому что Юникод и одна из его кодировок, UTF-8, стали наиболее распространенными.
Считайте, что Юникод – это огромная версия таблицы ASCII, в которой 1 114 112 возможных символов. Это от 0 до 1 114 111, или от 0 до 17 * (216) – 1, или 0x10ffff в шестнадцатеричном исчислении. Фактически, ASCII является подмножеством Unicode. Первые 128 символов в таблице Unicode в точности соответствуют символам ASCII, что вполне обоснованно.
В интересах технической точности, сам Юникод не является кодировкой. Скорее, Юникод реализуется различными кодировками символов, которые вы скоро увидите. Юникод лучше рассматривать как словарь (что-то вроде dict) или двухколоночную таблицу базы данных. Он отображает символы (такие как “a”, “¢” или даже “ቈ”) на отдельные целые положительные числа.
Юникод содержит практически все символы, которые вы можете себе представить, включая дополнительные непечатаемые символы. Один из моих любимых – назойливый знак “справа налево”, который имеет кодовую точку 8207 и используется в тексте, где есть как левосторонние, так и правосторонние языковые шрифты, например, в статье, содержащей абзацы на английском и арабском языках.
Примечание. В мире кодировок символов много тонких технических деталей, к которым некоторые люди любят придираться. Одна из таких деталей заключается в том, что только 1 111 998 символов Unicode действительно пригодны для использования по нескольким архаичным причинам.
Юникод против UTF-8
Не сразу люди поняли, что все символы мира не могут быть упакованы в один байт. Отсюда очевидно, что современные, более полные кодировки должны использовать несколько байт для кодирования некоторых символов.
Мы уже отметили, что Юникод технически не является полноценной кодировкой символов. Почему это так?
Есть одна вещь, о которой Юникод не говорит вам: он не указывает, как получить фактические биты из текста – только кодовые точки. Он не рассказывает достаточно о том, как преобразовать текст в двоичные данные и наоборот.
Юникод – это абстрактный стандарт кодирования, а не кодировка. Именно здесь в игру вступают UTF-8 и другие схемы кодирования. Стандарт Unicode (карта символов в кодовые точки) определяет несколько различных кодировок из единого набора символов.
UTF-8, а также его менее используемые родственники, UTF-16 и UTF-32, являются форматами кодирования для представления символов Юникода в виде двоичных данных по одному или более байт на символ. Мы обсудим UTF-16 и UTF-32 дальше.
Это подводит нас к определению, которое давно назрело. Что формально означает кодировать и декодировать?
Кодирование и декодирование в Python 3
Тип str в Python 3 предназначен для представления человекочитаемого текста и может содержать любой символ Юникода.
Тип bytes, наоборот, представляет двоичные данные или последовательности необработанных байтов, которые по своей сути не имеют кодировки.
Кодирование и декодирование – это процесс перехода от одного к другому:
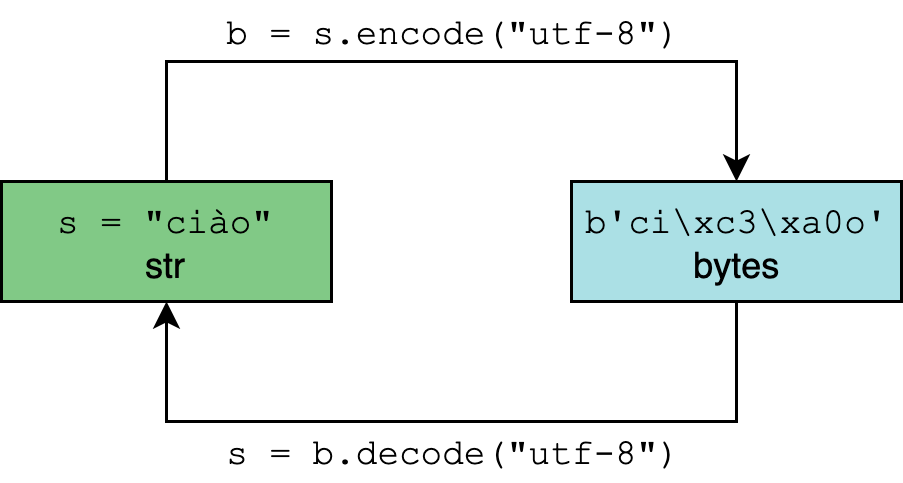
В .encode() и .decode() параметром кодировки по умолчанию является “utf-8”, хотя в целом безопаснее и однозначнее указывать его:
>>> "résumé".encode("utf-8")
b'r\xc3\xa9sum\xc3\xa9'
>>> "El Niño".encode("utf-8")
b'El Ni\xc3\xb1o'
>>> b"r\xc3\xa9sum\xc3\xa9".decode("utf-8")
'résumé'
>>> b"El Ni\xc3\xb1o".decode("utf-8")
'El Niño'
Результатом работы str.encode() является объект bytes. Как литералы байтов (например, b"r\xc3\xa9sum\xc3\xa9"), так и представления байтов допускают только символы ASCII.
Вот почему при вызове “El Niño”.encode(“utf-8”), ASCII-совместимое “El” разрешается представлять как есть, но n с тильдой экранируется в "\xc3\xb1". Эта беспорядочная последовательность представляет собой два байта, 0xc3 и 0xb1 в шестнадцатеричном формате:
>>> " ".join(f"{i:08b}" for i in (0xc3, 0xb1))
'11000011 10110001'
То есть, символ ñ требует два байта для двоичного представления в UTF-8.
Примечание. Если вы введете help(str.encode), вы, вероятно, увидите значение по умолчанию encoding='utf-8'. Будьте осторожны, исключая это и просто используя "résumé".encode(), потому что в Windows до Python 3.6 значение по умолчанию может быть другим.
Python 3: полностью на Юникод
Python 3 полностью поддерживает Юникод и UTF-8 в частности. Вот что это значит:
- Исходный код Python 3 по умолчанию считается UTF-8. Это означает, что вам не нужно добавлять
# -*- coding: UTF-8 -*-в верхней части файлов .py в Python 3. - Весь текст (str) по умолчанию является Юникодом. Кодированный текст Юникод представляется в виде двоичных данных (байтов). Тип str может содержать любой литеральный символ Unicode, например, “Δv / Δt”, и все они будут сохранены как Unicode.
- Python 3 принимает многие символы Unicode в идентификаторах. Это означает, что если вы вдруг решите назвать переменную
résumé = "~/Documents/resume.pdf", это будет работать. - Модуль re в Python по умолчанию использует флаг
re.UNICODE, а неre.ASCII. Это означает, что, например,r"\w"соответствует словарным символам Юникода, а не только буквам ASCII. - Кодировка по умолчанию в
str.encode()иbytes.decode()– UTF-8.
Есть еще одно свойство, более тонкое: кодировка по умолчанию для встроенной функции open() зависит от платформы и от значения параметра locale.getpreferredencoding():
>>> # Mac OS X High Sierra >>> import locale >>> locale.getpreferredencoding() 'UTF-8' >>> # Windows Server 2012; other Windows builds may use UTF-16 >>> import locale >>> locale.getpreferredencoding() 'cp1252'
И снова урок: будьте осторожны с предположениями об универсальности UTF-8, даже если это преобладающая кодировка. Никогда не помешает явно указывать кодировку в своем коде.
Один байт, два байта, три байта, четыре байта
Одной из ключевых особенностей UTF-8 является переменная длина кодирования. Соблазнительно пропустить это объяснение, но стоит в него погрузиться более глубоко.
Вспомните раздел об ASCII. Она требует не более одного байта пространства. Вы можете быстро доказать это с помощью следующего выражения генератора:
>>> all(len(chr(i).encode("ascii")) == 1 for i in range(128))
True
UTF-8 совсем другая. Один символ Юникода может занимать от одного до четырех байт. Вот пример одного символа Юникода, занимающего четыре байта:
>>> ibrow = "🤨"
>>> len(ibrow)
1
>>> ibrow.encode("utf-8")
b'\xf0\x9f\xa4\xa8'
>>> len(ibrow.encode("utf-8"))
4
>>> # Calling list() on a bytes object gives you
>>> # the decimal value for each byte
>>> list(b'\xf0\x9f\xa4\xa8')
[240, 159, 164, 168]
Это тонкая, но важная особенность функции len():
- Длина одного символа Юникод в виде строки Python всегда будет равна 1, независимо от того, сколько байт он занимает.
- Длина того же символа, закодированного в байтах, будет находиться в диапазоне от 1 до 4.
В таблице ниже приведены общие типы символов, которые помещаются в диапазоны длины символа:
| Десятичный диапазон | Шестнадцатеричный диапазон | Включаемые символы | Примеры |
|---|---|---|---|
| 0-127 | \u0000 – \u007F | Символы US-ASCII | “A”, “\n”, “7”, “&” |
| 128-2047 | \u0080 – \u07FF | Большинство латинских алфавитов* | “ę”, “±”, “ƌ”, “ñ” |
| 2048-65535 | \u0800 – \uFFFF | Дополнительные символы многоязыковой плоскости (BMP)** | “ത”, “ᄇ”, “ᮈ”, “‰” |
| 65536-1114111 | \U00010000 – \U0010FFFF | Другие*** | “𝕂”, “𐀀”, “😓”, “🂲” |
*Латинские алфавиты, такие как английский, арабский, греческий и ирландский.
**Включает широкий спектр языков и символов, в основном китайских, японских и корейских (а также символы ASCII и латинские алфавиты).
***Дополнительные символы китайского, японского, корейского и вьетнамского языков, а также больше символов и эмодзи.
Примечание. В целях сохранения общего представления, здесь не рассматриваются дополнительные технические особенности UTF-8, которые редко видимы для пользователя Python.
Например, UTF-8 фактически использует префиксные коды, которые указывают на количество байтов в последовательности. Это позволяет декодеру определить, какие байты принадлежат друг другу в кодировке переменной длины, и позволяет первому байту служить индикатором количества байтов в следующей последовательности.
Статья о UTF-8 на Википедии не стесняется технических деталей. К тому же, всегда есть официальный стандарт Unicode, в котором можно найти все подробности.
Что насчет UTF-16 и UTF-32?
Давайте вернемся к двум другим вариантам кодировки, UTF-16 и UTF-32.
На практике разница между ними и UTF-8 существенна. Вот пример того, насколько велика разница при преобразовании туда и обратно:
>>> letters = "αβγδ"
>>> rawdata = letters.encode("utf-8")
>>> rawdata.decode("utf-8")
'αβγδ'
>>> rawdata.decode("utf-16") # 😧
'뇎닎돎듎'
В данном случае кодирование четырех греческих букв в UTF-8, а затем обратное декодирование в текст в UTF-16 приведет к созданию текстовой строки на совершенно другом языке (корейском).
Подобные вопиюще неверные результаты возможны, когда для преобразований “туда и обратно” используется не одна и та же кодировка. Два варианта декодирования одного и того же байтового объекта могут дать результаты, которые даже не будут на одном языке.
В этой таблице приведен диапазон или количество байтов в кодировках UTF-8, UTF-16 и UTF-32:
| Кодировка | Байтов на символ (включительно) | Переменная длина |
|---|---|---|
| UTF-8 | 1 до 4 | Да |
| UTF-16 | 2 до 4 | Да |
| UTF-32 | 4 | Нет |
Еще один любопытный аспект семейства UTF заключается в том, что UTF-8 не всегда будет занимать меньше места, чем UTF-16. Это может показаться математически контринтуитивным, но это вполне возможно:
>>> text = "記者 鄭啟源 羅智堅"
>>> len(text.encode("utf-8"))
26
>>> len(text.encode("utf-16"))
22
Причина в том, что символы в диапазоне от U+0800 до U+FFFF (от 2048 до 65535 в десятичной системе) занимают три байта в UTF-8 против всего двух в UTF-16.
Я ни в коем случае не рекомендую вам вскочить на поезд UTF-16, независимо от того, работаете ли вы на языке, символы которого часто встречаются в этом диапазоне. Среди прочих причин, одним из веских аргументов в пользу использования UTF-8 является то, что в мире кодировок слиться с толпой – отличная идея.
Не говоря уже о том, что сейчас компьютерная память стоит дешево, поэтому экономия 4 байт за счет использования UTF-16, вероятно, не окупится.
Встроенные функции Python, связанные с системами счисления и кодировкой символов
Вы справились с самой трудной частью. Пришло время использовать то, что вы уже видели в Python.
В Python есть группа встроенных функций, которые так или иначе, связаны с системами счисления и кодировкой символов:
Их можно логически сгруппировать в зависимости от их назначения:
ascii(),bin(),hex()иoct()предназначены для получения различных представлений входных данных. Каждая из них выдает строку. Первая,ascii(), выдает представление объекта только в формате ASCII, при этом символы, не относящиеся к ASCII, экранируются. Остальные три дают двоичное, шестнадцатеричное и восьмеричное представления целого числа, соответственно. Это только представления, а не фундаментальное изменение входных данных.bytes(),str()иint()– это конструкторы класса для соответствующих типов,bytes,strиint. Каждый из них предлагает способы приведения входных данных к нужному типу. Например, хотя вариантint(11.0), вероятно, более распространен, вы также можете явно указать систему исчисления, отличную от 10:int('11', base=16).- Функции
ord()иchr()обратны друг другу в том смысле, что функцияord()преобразует символstrв его кодовую точку с основанием 10, аchr()делает обратное.
Вот более подробный обзор каждой из этих девяти функций:
| Функция | Сигнатура | Принимает | Тип возвращаемого значения | Назначение |
|---|---|---|---|---|
| ascii() | ascii(obj) | Разные типы obj | str | Только ASCII-представление объекта. С символами, не являющимися ASCII – экранирует |
| bin() | bin(number) | number: int | str | Двоичное представление целого числа с префиксом “0b” |
| bytes() | bytes(iterable_of_ints) bytes(s, enc[, errors]) bytes(bytes_or_buffer) bytes([i]) | Разные типы входных данных | bytes | Приведение входных данных к типу bytes, сырые бинарные данные |
| chr() | chr(i) | i: int i>=0 i<=1114111 | str | Преобразование целочисленной кодовой точки в отдельный символ Юникода |
| hex() | hex(number) | number: int | str | Шестнадцатеричное представление целого числа с префиксом “0x” |
| int() | int([x]) int(x, base=10) | Разные типы входных данных | int | Приведение входных данных к типу int |
| oct() | oct(number) | number: int | str | Восьмеричное представление целого числа с префиксом “0o” |
| ord() | ord(c) | c: str len(c) == 1 | int | Преобразование отдельного символа Юникода в его целочисленную кодовую точку |
| str() | str(object=’‘) str(b[, enc[, errors]]) | Разные типы входных данных | str | Приведение входных данных к типу str, текстовое представление |
Примеры использования функций
ascii()
ascii() дает вам представление объекта только в формате ASCII, с экранированием символов, не относящихся к ASCII:
>>> ascii("abcdefg")
"'abcdefg'"
>>> ascii("jalepeño")
"'jalepe\\xf1o'"
>>> ascii((1, 2, 3))
'(1, 2, 3)'
>>> ascii(0xc0ffee) # Hex literal (int)
'12648430'
bin()
bin() дает двоичное представление целого числа с префиксом “0b”:
>>> bin(0) '0b0' >>> bin(400) '0b110010000' >>> bin(0xc0ffee) # Hex literal (int) '0b110000001111111111101110' >>> [bin(i) for i in [1, 2, 4, 8, 16]] # `int` + list comprehension ['0b1', '0b10', '0b100', '0b1000', '0b10000']
bytes()
bytes() преобразует входные данные в байты, представляющие собой необработанные двоичные данные:
>>> # Iterable of ints
>>> bytes((104, 101, 108, 108, 111, 32, 119, 111, 114, 108, 100))
b'hello world'
>>> bytes(range(97, 123)) # Iterable of ints
b'abcdefghijklmnopqrstuvwxyz'
>>> bytes("real 🐍", "utf-8") # String + encoding
b'real \xf0\x9f\x90\x8d'
>>> bytes(10)
b'\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00'
>>> bytes.fromhex('c0 ff ee')
b'\xc0\xff\xee'
>>> bytes.fromhex("72 65 61 6c 70 79 74 68 6f 6e")
b'realpython'
chr()
chr() преобразует целочисленную кодовую точку в один символ Юникода:
>>> chr(97) 'a' >>> chr(7048) 'ᮈ' >>> chr(1114111) '\U0010ffff' >>> chr(0x10FFFF) # Hex literal (int) '\U0010ffff' >>> chr(0b01100100) # Binary literal (int) 'd'
hex()
hex() дает шестнадцатеричное представление целого числа с префиксом “0x”:
>>> hex(100) '0x64' >>> [hex(i) for i in [1, 2, 4, 8, 16]] ['0x1', '0x2', '0x4', '0x8', '0x10'] >>> [hex(i) for i in range(16)] ['0x0', '0x1', '0x2', '0x3', '0x4', '0x5', '0x6', '0x7', '0x8', '0x9', '0xa', '0xb', '0xc', '0xd', '0xe', '0xf']
int()
int() приводит входные данные к значению int, по желанию интерпретируя их в заданной системе исчисления:
>>> int(11.0)
11
>>> int('11')
11
>>> int('11', base=2)
3
>>> int('11', base=8)
9
>>> int('11', base=16)
17
>>> int(0xc0ffee - 1.0)
12648429
>>> int.from_bytes(b"\x0f", "little")
15
>>> int.from_bytes(b'\xc0\xff\xee', "big")
12648430
ord()
Функция ord() преобразует один символ Unicode в его целочисленную кодовую точку:
>>> ord("a")
97
>>> ord("ę")
281
>>> ord("ᮈ")
7048
>>> [ord(i) for i in "hello world"]
[104, 101, 108, 108, 111, 32, 119, 111, 114, 108, 100]
str()
str() преобразует входные данные в str, печатный текст:
>>> str("str of string")
'str of string'
>>> str(5)
'5'
>>> str([1, 2, 3, 4]) # Like [1, 2, 3, 4].__str__(), but use str()
'[1, 2, 3, 4]'
>>> str(b"\xc2\xbc cup of flour", "utf-8")
'¼ cup of flour'
>>> str(0xc0ffee)
'12648430'
Строковые литералы Python
Вместо того чтобы использовать конструктор str(), обычно принято вводить строку в буквальном смысле:
>>> meal = "shrimp and grits"
Интересно то, что Python 3 полностью ориентирован на Юникод. Вы можете “вводить” символы Юникода, которые, скорее всего, отсутствуют на вашей клавиатуре. Т.е. можно просто скопировать их и вставить прямо в оболочку интерпретатора Python 3.
>>> alphabet = 'αβγδεζηθικλμνξοπρςστυφχψ' >>> print(alphabet) αβγδεζηθικλμνξοπρςστυφχψ
Помимо вывода в консоль фактических символов Юникода без кодировки, существуют и другие способы ввода строк Юникода.
Одним из самых плотных разделов документации Python является раздел о лексическом анализе, в частности, раздел о строковых и байтовых литералах. Лично мне пришлось прочитать этот раздел несколько раз, чтобы он действительно стал понятен.
В нем говорится, что в Python существует до шести способов ввода одного и того же символа Unicode.
Первый и самый распространенный способ – набрать сам символ буквально, без всякого экранирования, как вы уже видели. Самое сложное в этом методе – найти фактические нажатия клавиш. Вот тут-то и вступают в игру другие методы получения и представления символов. Вот полный список:
| Последовательность символов | Значение | Как выразить “a” |
|---|---|---|
| “\ooo” | Символ с восьмеричным значением ooo | “\141” |
| “\xhh” | Символ с шестнадцатеричным значением hh | “\x61” |
| “\N{name}” | Символ с именем name из базы данных Юникода | “\N{LATIN SMALL LETTER A}” |
| “\uxxxx” | Символ с шестнадцатеричным значением xxxx (16 бит) | “\u0061” |
| “\Uxxxxxxxx” | Символ с шестнадцатеричным значением xxxxxxxx (32 бита) | “\U00000061” |
Вот некоторые доказательства и подтверждение вышеизложенного:
>>> (
... "a" ==
... "\x61" ==
... "\N{LATIN SMALL LETTER A}" ==
... "\u0061" ==
... "\U00000061"
... )
True
Здесь есть два основных предостережения:
- Не все эти формы работают для всех символов. Шестнадцатеричное представление целого числа 300 – 0x012c – просто не поместится в 2-шестизначный escape-код
"\xhh". Наивысшая точка кода, которую можно втиснуть в этот код, это"\xff"(“ÿ”). Аналогично для"\ooo": форма будет работать только до"\777"(“ǿ”). - Для
\xhh,\uxxxxи\Uxxxxxтребуется ровно столько цифр, сколько показано в этих примерах. Это может сбить вас с толку из-за того, что таблицы Unicode традиционно отображают коды символов с ведущим U+ и переменным количеством шестнадцатеричных символов. Ключевым моментом является то, что в таблицах Юникода чаще всего эти коды не обнуляются.
Например, если вы обратитесь к сайту unicode-table.com за информацией о готической букве faihu (или fehu), “𐍆”, то увидите, что она имеет код U+10346.
Как это можно записать в "\uxxxx" или "\Uxxxxx"? Ну, вы не можете поместить его в "\uxxxx", потому что это 4-байтовый символ, и чтобы использовать "\Uxxxxxxx" для представления этого символа, вам потребуется дополнить последовательность слева:
>>> "\U00010346" '𐍆'
Это также означает, что форма "\Uxxxxxxxxxx" является единственной управляющей последовательностью, которая может содержать любой символ Unicode.
Примечание. Вот короткая функция для преобразования строк, которые выглядят как "U+10346", в то, с чем может работать Python. Она использует str.zfill():
>>> def make_uchr(code: str):
... return chr(int(code.lstrip("U+").zfill(8), 16))
>>> make_uchr("U+10346")
'𐍆'
>>> make_uchr("U+0026")
'&'
Другие кодировки, доступные в Python
До сих пор вы познакомились с четырьмя кодировками символов:
- ASCII
- UTF-8
- UTF-16
- UTF-32
Существует множество других кодировок.
Одним из примеров является Latin-1 (также называемая ISO-8859-1), которая технически является стандартом по умолчанию для протокола передачи гипертекста (HTTP), согласно RFC 2616. Windows имеет свой собственный вариант Latin-1 под названием cp1252.
Примечание. ISO-8859-1 до сих пор широко используется. Библиотека requests следует рекомендации RFC 2616 и использует эту кодировку в качестве кодировки по умолчанию для содержимого HTTP- или HTTPS-ответа. Если в заголовке Content-Type найдено слово “text”, и другая кодировка не указана, то requests будет использовать ISO-8859-1.
Полный список принятых кодировок находится далеко внизу в документации к модулю codecs, который является частью стандартной библиотеки Python.
Еще одна полезная распознаваемая кодировка, о которой стоит знать, – это “unicode-escape”. Если у вас есть раскодированная строка (str) и вы хотите быстро получить ее представление в виде экранированного литерала Unicode, вы можете указать эту кодировку при использовании метода .encode():
>>> alef = chr(1575) # Or "\u0627"
>>> alef_hamza = chr(1571) # Or "\u0623"
>>> alef, alef_hamza
('ا', 'أ')
>>> alef.encode("unicode-escape")
b'\\u0627'
>>> alef_hamza.encode("unicode-escape")
b'\\u0623'
Вы знаете, что говорят о предположениях…
То, что Python предполагает использование кодировки UTF-8 для файлов и генерируемого вами кода, не означает, что вы как программист можете опираться на предположения относительно внешних данных.
Повторим это еще раз, потому что это правило, по которому нужно жить: когда вы получаете двоичные данные (байты) из стороннего источника, будь то файл или запрос по сети, лучшей практикой является проверка того, что в данных указана кодировка. Если это не так, то вы должны спросить об этом.
Весь ввод-вывод происходит в байтах, а не в тексте, а байты для компьютера – это просто единицы и нули, пока вы не сообщите ему обратное, указав кодировку.
Вот пример того, как все может пойти не так. Вы делаете запрос по API, который отдает вам рецепт дня, который вы получаете в байтах и всегда без проблем декодировали с помощью .decode("utf-8"). В этот конкретный день часть рецепта выглядит следующим образом:
>>> data = b"\xbc cup of flour"
Похоже, что в рецепте требуется немного муки, но мы не знаем, сколько именно:
>>> data.decode("utf-8")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xbc in position 0: invalid start byte
О-о-о. Ошибка UnicodeDecodeError, которая может укусить вас, когда вы делаете предположения о кодировке. Вы проверяете метод API. И вот оно, данные действительно передаются в кодировке Latin-1:
>>> data.decode("latin-1")
'¼ cup of flour'
Вот так. В кодировке Latin-1 каждый символ помещается в один байт, тогда как в UTF-8 символ “¼” занимает два байта (“\xc2\xbc”).
Урок заключается в том, что может быть опасно принимать на веру кодировку любых данных, которые вам передают. Обычно в наши дни это UTF-8, но именно тот небольшой процент случаев, когда это не так, может привести к плохим последствиям.
Если вам действительно нужно угадать кодировку, посмотрите на библиотеку chardet, которая использует методологию Mozilla для обоснованного определения неоднозначно закодированного текста. Тем не менее, такой инструмент, как chardet, должен быть вашим последним средством, а не первым.
Дополнительно: unicodedata
Нельзя не упомянуть unicodedata из стандартной библиотеки Python, которая позволяет взаимодействовать с базой данных символов Юникода (UCD) и выполнять поиск по ней:
>>> import unicodedata
>>> unicodedata.name("€")
'EURO SIGN'
>>> unicodedata.lookup("EURO SIGN")
'€'
Подведение итогов
В этой статье мы разобрали обширную и внушительную тему кодирования символов в Python.
Вы проделали большой объем работы, ознакомившись с такими темами, как:
- Фундаментальные концепции кодировок символов и систем исчисления.
- Целочисленные, двоичные, восьмеричные, шестнадцатеричные, строковые и байтовые литералы в Python.
- Встроенные функции Python, связанные с кодировкой символов и системами исчисления.
- Отношение Python 3 к текстовым и двоичным данным.
А теперь идите и практикуйте полученные знания!
Пингбэк: Строковый метод Python encode()
Спасибо за статью, хочется узнать есть ли способы измерения самих символов по длине, относительно стандартных из ASCII?
И возможно ли перекодировать символы? т.е. Сделать свои символы, по своему рисунку?