
Предыдущая статья – Распознавание образов на Python: Часть IX – базовое тестирование.
Теперь давайте попробуем визуализировать наши результаты. Мы рассмотрим еще несколько примеров, а затем поговорим о некоторых идеях для продвижения вперед.
Вот полный код нашей серии, модифицированный для использования в нем библиотеки matplotlib:
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
import time
from collections import Counter
from matplotlib import style
style.use("ggplot")
def createExamples():
numberArrayExamples = open('numArEx.txt','a')
numbersWeHave = range(1,10)
for eachNum in numbersWeHave:
for furtherNum in numbersWeHave:
imgFilePath = 'images/numbers/'+str(eachNum)+'.'+str(furtherNum)+'.png'
ei = Image.open(imgFilePath)
eiar = np.array(ei)
eiarl = str(eiar.tolist())
lineToWrite = str(eachNum)+'::'+eiarl+'\n'
numberArrayExamples.write(lineToWrite)
def threshold(imageArray):
balanceAr = []
newAr = imageArray
for eachPart in imageArray:
for theParts in eachPart:
# for the reduce(lambda x, y: x + y, theParts[:3]) / len(theParts[:3])
# in Python 3, just use: from statistics import mean
# then do avgNum = mean(theParts[:3])
avgNum = reduce(lambda x, y: x + y, theParts[:3]) / len(theParts[:3])
balanceAr.append(avgNum)
balance = reduce(lambda x, y: x + y, balanceAr) / len(balanceAr)
for eachRow in newAr:
for eachPix in eachRow:
if reduce(lambda x, y: x + y, eachPix[:3]) / len(eachPix[:3]) > balance:
eachPix[0] = 255
eachPix[1] = 255
eachPix[2] = 255
eachPix[3] = 255
else:
eachPix[0] = 0
eachPix[1] = 0
eachPix[2] = 0
eachPix[3] = 255
return newAr
def whatNumIsThis(filePath):
matchedAr = []
loadExamps = open('numArEx.txt','r').read()
loadExamps = loadExamps.split('\n')
i = Image.open(filePath)
iar = np.array(i)
iarl = iar.tolist()
inQuestion = str(iarl)
for eachExample in loadExamps:
try:
splitEx = eachExample.split('::')
currentNum = splitEx[0]
currentAr = splitEx[1]
eachPixEx = currentAr.split('],')
eachPixInQ = inQuestion.split('],')
x = 0
while x < len(eachPixEx):
if eachPixEx[x] == eachPixInQ[x]:
matchedAr.append(int(currentNum))
x+=1
except Exception as e:
print(str(e))
x = Counter(matchedAr)
print(x)
graphX = []
graphY = []
ylimi = 0
for eachThing in x:
graphX.append(eachThing)
graphY.append(x[eachThing])
ylimi = x[eachThing]
fig = plt.figure()
ax1 = plt.subplot2grid((4,4),(0,0), rowspan=1, colspan=4)
ax2 = plt.subplot2grid((4,4),(1,0), rowspan=3,colspan=4)
ax1.imshow(iar)
ax2.bar(graphX,graphY,align='center')
plt.ylim(400)
xloc = plt.MaxNLocator(12)
ax2.xaxis.set_major_locator(xloc)
plt.show()
whatNumIsThis('images/test.png')
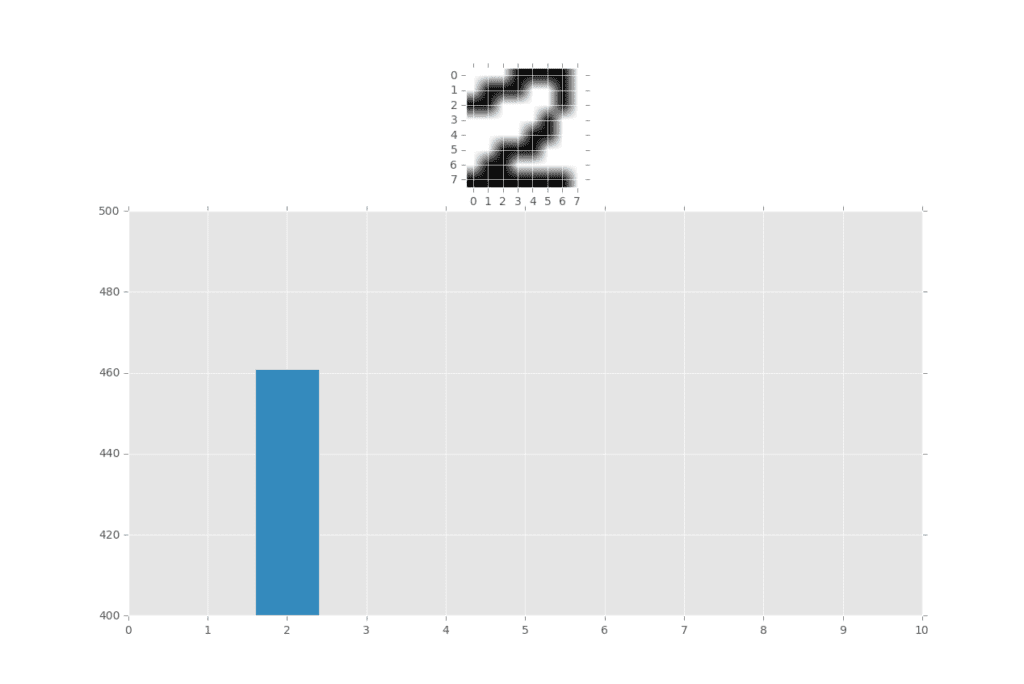
Советуем вам открыть какой-нибудь графический редактор, Paint например, или что-то в этом духе, создать в нем квадрат 8 Х 8, а внутри него нарисовать какую-нибудь цифру. Конечно, можно было бы взять ее из обучающей выборки, но это было бы методологически неправильно.
Нарисовав цифру, подвигайте ее в разные стороны.
Вы должны преуспеть, хотя очевидно, что может возникнуть и много проблем. До сих пор мы нормализовали изображения, размер которых был строго 8 Х 8. А так везти будет не всегда, и очевидно, что вам еще и придется менять размер. Толщина линий у нас также всегда была довольно стандартной.
Основная цель данной серии статей состоит в том, чтобы показать, что распознавание образов представляет собой весьма сложную задачу, но ее всегда можно разбить на подзадачи и таким образом решить при помощи простого и понятного кода. Надеемся, что вам все понравилось.
Перевод статьи “Testing, visualization, and moving forward”.
Пингбэк: Распознавание образов на Python. Часть IX – базовое тестирование - pythonturbo