
Pandas – одна из самых популярных и используемых библиотек Python. Функций в ней так много, что бывает трудно запомнить все. Но запомнить основые вполне возможно. В этой статье мы рассмотрим некоторые функции Pandas из числа наиболее используемых.
1. Считывание CSV-файла
Существует множество случаев, когда данные представлены в CSV-файле. Для загрузки таких файлов мы используем функцию read_csv(). Она имеет следующие параметры:
filepath– адрес файла для чтения в кавычкахsepдля указания разделителя (по умолчанию – запятая)headerдля указания номера строки, содержащей метки столбцовnames(опциональный) для явного указания меток столбцовindex_col(опциональный) для указания, какой столбец используется в качестве меток строк
Пример:
df = pd.read_csv('train.csv')
Примечание редакции: подробнее о чтении CSV читайте в статье “Как прочитать CSV-файл в Python”.
2. head() и tail()
Для отображения первых и последних строк данных мы используем функции head() и tail() соответственно. Мы можем указать, сколько строк нужно вывести, передав число в функцию. По умолчанию она выводит пять строк.
Эти функции очень удобны для просмотра больших наборов данных, поскольку избавляет от необходимости прокрутки всего набора.
Вывод первых строк:
df.head()
Результат:

Вывод двух последних строк:
df.tail(2)
Результат:

3. Shape
Для отображения размеров DataFrame, т.е. количества строк и столбцов, мы используем атрибут shape.
df.shape # Результат: #(891, 12)
4. info()
Эта функция используется для отображения информации о DataFrame, такой как номера, метки и типы данных столбцов, использование памяти, индекс диапазона и количество значений в каждом столбце (ненулевые значения).
df.info()
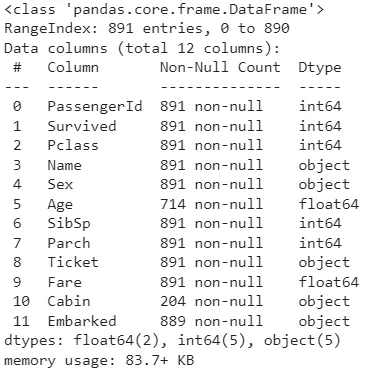
Функция info() выводит общее количество записей в данных вместе с диапазоном. Приведенные данные имеют 11 столбцов, которые относятся к типам float, int и object (string). Они занимают 83,7 КБ памяти.
5. Describe
С помощью функции Pandas describe() мы можем вывести множество статистических значений в нескольких столбцах при помощи всего одной строки кода.
Для непрерывных переменных эта функция возвращает количество, среднее значение, медиану, стандартное отклонение, 25-й и 75-й процентили, максимальное и минимальное значения.
df.describe()
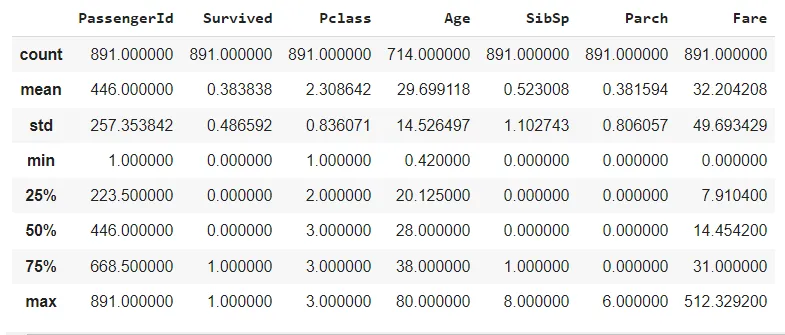
Функция describe() имеет параметр percentiles, в котором мы можем указать перцентили, которые хотим включить в вывод.
По умолчанию функция выдает статистическую сводку только для числовых переменных. Для отображения других переменных можно указать параметр include.
df.describe(include='all')
Результат:
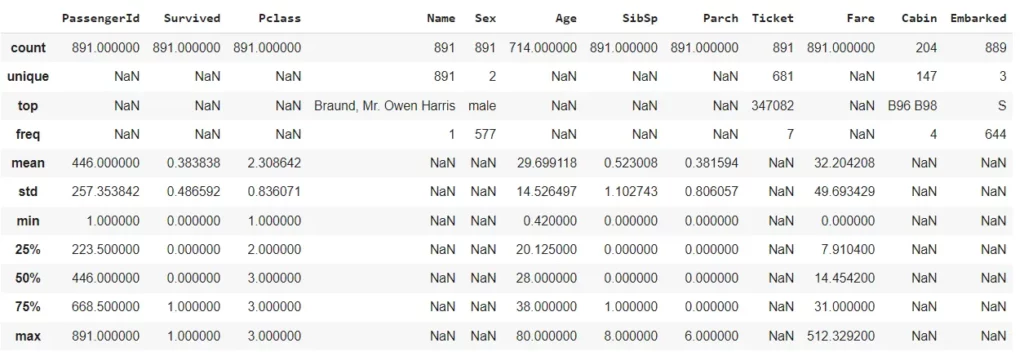
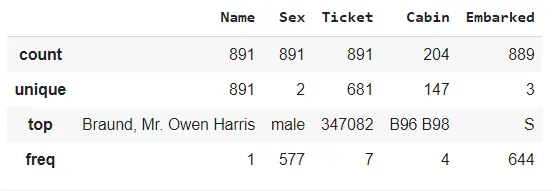
Для категориальных переменных функция возвращает общее количество, количество уникальных значений, наиболее частое значение и его частоту.
Мы можем указать, хотим ли мы отображать только столбцы одного типа, например, числовые, объектные или категориальные. Давайте выведем только строковые:
df.describe(include = [np.object]) # используйте include = ['category'] для категориальных столбцов # используйте include = [np.number] для числовых столбцов
Результат:
Мы также можем использовать describe() для конкретного столбца (столбцов). Если же мы хотим удалить некоторые столбцы из сводки статистики, можно использовать параметр exclude.
6. value_counts
Для вычисления и отображения частотности каждого значения в столбце DataFrame используется функция value_counts().
df['Survived'].value_counts() # Результат: # 0 549 # 1 342 # Name: Survived, dtype: int64
Мы можем получить процентные значения для каждого уникального элемента в столбце, используя аргумент normalize=True.
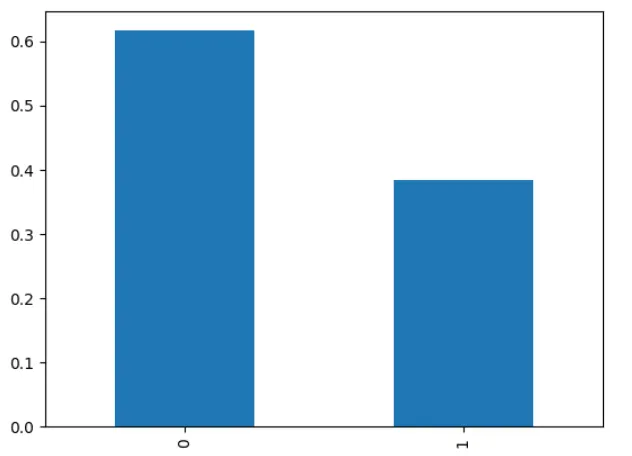
df['Survived'].value_counts(normalize=True)*100 # Результат: # 0 61.616162 # 1 38.383838 # Name: Survived, dtype: float64
Для наглядного представления чисел можно вывести график:
df['Survived'].value_counts(normalize=True).plot.bar()
7. Drop
Иногда нам необходимо удалить из данных некоторые столбцы и строки. Для этого используется функция drop().
С помощью параметра axis мы можем сообщить, столбец это или строка.
# столбец df.drop(['Ticket'], axis=1, inplace=True) # строка df.drop(3, axis=0, inplace=True
Как вы уже поняли, axis=1 указывает на столбец, а axis=0 – на строку. inplace=True означает, что изменения сохраняются в исходном DataFrame.
8. Columns
Для отображения имен столбцов в DataFrame мы используем атрибут columns.
df.columns # Результат: # Index(['PassengerId', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp', # 'Parch', 'Fare', 'Cabin', 'Embarked'], # dtype='object')
9. rename()
Часто имена столбцов имеют нестандартный формат. Чтобы их изменить, мы используем функцию rename(). Для этого в функцию нужно передать текущее имя столбца и его новое имя:
df.rename(columns={'PassengerId' : 'ID'}, inplace=True)
Примечание редакции: об этом и других изменениях в столбцах читайте в статье “Обновление строк и столбцов в Pandas”.
10. unique() и nunique()
Для нахождения всех уникальных значений в столбце используется функция unique(), а для нахождения их количества – функция nunique().
df['Embarked'].unique() # array(['S', 'C', 'Q', nan], dtype=object) df['Embarked'].nunique() # 3
Функция unique() включает значения nan, а функция unique() исключает их.
Перевод статьи «The Most Used Functions of Pandas».
очень полезно! спасибо!