
Строка – это тип данных, состоящий из символов, заключенных в кавычки. Элементы строки могут быть буквами, цифрами и другими символами. Для работы со строками Python предоставляет множество встроенных методов. Один из них – метод .lower(), позволяющий перевести буквенные символы строки в нижний регистр. В этой статье мы рассмотрим на примерах работу .lower(), а также разберем, как иначе можно сделать символы строки строчными.
Как перевести строку в нижний регистр с помощью .lower()
Строки могут состоять из различных символов, в том числе из букв. Причем буквы могут быть как строчными, так и заглавными, т.е. стоять как в нижнем, так и в верхнем регистре.
В Python есть встроенный метод .lower(), который может заменить все буквы в строке, стоящие в верхнем регистре, на те же буквы, но в нижнем. Этот метод можно применять не только к строкам, содержащим исключительно заглавные буквы. Он работает и со строками, где использованы оба регистра, и со строками, содержащими другие символы.
name = "BOB STONE" print(name.lower()) name1 = "Ruby Roundhouse" print(name1.lower()) name2 = "joHN Wick" print(name2.lower()) name3 = "charlieNew" print(name3.lower()) example = "abRa--5$$-cadABRa" print(example.lower())
Результат:
bob stone ruby roundhouse john wick charlienew abra--5$$-cadabra
Как видите, все заглавные буквы во всех строках преобразованы в строчные. При этом буквы, которые изначально были строчными, и небуквенные символы оставлены без изменений.
Другие способы сделать все буквы строки строчными
Помимо встроенного метода .lower(), в Python есть и другие способы перевести строку в нижний регистр. Мы рассмотрим два из них.
Основная идея заключается в том, чтобы перебрать в цикле все буквы строки и заменить прописные на строчные. Разница между двумя подходами, которые мы рассмотрим, в способе выявления заглавных букв. Первый способ предполагает создание списка букв и сверку с ним символов строки, а второй – использование кодов символов в Unicode.
Как перевести строку в нижний регистр, используя цикл и список букв
Сначала создайте переменную, в которой будет храниться строка с прописными буквами, полученная от пользователя. Затем создайте другую переменную, в которой будет храниться список всех букв английского алфавита в нижнем и верхнем регистре. И наконец, создайте последнюю переменную, в которой будут храниться строчные буквы.
word = str(input("Enter a word: "))
alphabet = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u',
'v', 'w', 'x', 'y', 'z', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P',
'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z']
lowercase_letters = ''
В английском алфавите 26 букв, поэтому длина списка alphabet – 52, а индекс последнего элемента – 51 (поскольку индексация начинается с нуля).
Мы также видим, что сначала в списке идут строчные буквы. Индексы строчных букв находятся в диапазоне от 0 до 25, а индексы прописных букв – от 26 до 51.
Далее мы при помощи цикла for перебираем все символы в строке:
for char in word:
char – это имя новой переменной, в которую помещаются все символы из переменной word поочередно.
Пользователь может передать нам как строку, содержащую только заглавные буквы, так и строку, содержащую также строчные буквы, цифры и прочие символы.
Случай 1. Строка, состоящая исключительно из заглавных букв
Чтобы перевести такую строку в нижний регистр, нужно для каждой буквы строки найти индекс такой же буквы в списке. Для получения индекса мы используем метод .index():
alphabet = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u',
'v', 'w', 'x', 'y', 'z', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P',
'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z']
word = str(input("Enter a word: "))
for char in word:
print(alphabet.index(char))
Результат:
Enter a word: GIRL 32 34 43 37
В списке строчные буквы имеют индексы от 0 до 25, а заглавные – от 26 до 51. Мы добавляем блок условия, в котором проверяем, является буква строчной или заглавной. Если индекс буквы больше 25, то буква заглавная.
Чтобы получить соответствующие строчные буквы, мы вычитаем 26 из каждого индекса заглавной буквы. Получив индексы строчных букв, мы находим по ним соответствующие буквы. Найденные строчные буквы добавляются в переменную lowercase_letters, которая вначале хранит пустую строку. Наконец, мы возвращаем переменную lowercase_letters, печатая ее вне цикла.
for char in word:
if alphabet.index(char) > 25:
lowercase_letters += alphabet[alphabet.index(char) - 26]
print(lowercase_letters)
Вот как выглядит код функции для перевода строки в нижний регистр:
def change_to_lowercase(word):
alphabet = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u',
'v', 'w', 'x', 'y', 'z', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P',
'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z']
lowercase_letters = ''
for char in word:
if alphabet.index(char) > 25:
lowercase_letters += alphabet[alphabet.index(char) - 26]
return lowercase_letters
word = str(input("Enter a word: "))
print(change_to_lowercase(word=word))
# Результат:
# Enter a word: GIRL
# girl
Случай 2: строка с буквами в обоих регистрах, а также со специальными символами и цифрами
Переводя такую строку в нижний регистр, необходимо проверить некоторые условия. Нам нужно знать, является ли символ строки:
- небуквенным символом (например, цифрой или специальным символом)
- буквой в нижнем регистре.
Такие символы добавляются в lowercase_letters без изменений.
Чтобы проверить, является ли символ небуквенным, мы используем ключевое слово not in.
Примечание редакции: рекомендуем почитать статью “Операторы in и not in в Python”.
Чтобы проверить, является ли символ строчным, мы находим его индекс. Опять же, строчные буквы имеют индексы 0-25 в списке alphabet, и индекс последней строчной буквы равен 25.
Строчные буквы и небуквенные символы добавляются в переменную lowercase_letters, которая вначале хранит пустую строку.
for char in word:
if char not in alphabet or alphabet.index(char) <= 25:
lowercase_letters += char
В приведенном выше блоке кода мы использовали метод .index(), чтобы найти индекс буквы в списке alphabet.
У оставшихся символов, которые, как мы предполагаем, являются прописными буквами, индексы входят в диапазон 26-51. Чтобы найти соответствующие им индексы строчных букв, мы вычитаем 26. Конечный результат добавляем к переменной lowercase_letters и выводим ее вне цикла:
for char in word:
if char not in alphabet or alphabet.index(char) <= 25:
lowercase_letters += char
else:
lowercase_letters += alphabet[alphabet.index(char) - 26]
print(lowercase_letters)
Вот как выглядит код функция для перевода любой строки в нижний регистр:
def change_to_lowercase(word):
alphabet = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u',
'v', 'w', 'x', 'y', 'z', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P',
'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z']
lowercase_letters = ''
for char in word:
if char not in alphabet or alphabet.index(char) <= 25:
lowercase_letters += char
else:
lowercase_letters += alphabet[alphabet.index(char) - 26]
return lowercase_letters
word = str(input("Enter a word: "))
print(change_to_lowercase(word=word))
# Результат:
# Enter a word: 2022BlackADAM&&
# 2022blackadam&&
# Enter a word: Weasle2@3568QQQAJHGB
# weasle2@3568qqqajhgb
Как перевести строку в нижний регистр, используя стандарт Unicode
Unicode означает универсальный стандарт символов. Согласно сайту unicode.org,
“Стандарт Unicode обеспечивает уникальный номер для каждого символа, независимо от платформы, устройства, приложения или языка”.
Проще говоря, все буквы из разных языков имеют уникальные номера.
Прежде чем перейти к объяснению кода, приведем таблицу, содержащую все уникальные коды для букв английского алфавита, как строчных, так и прописных.
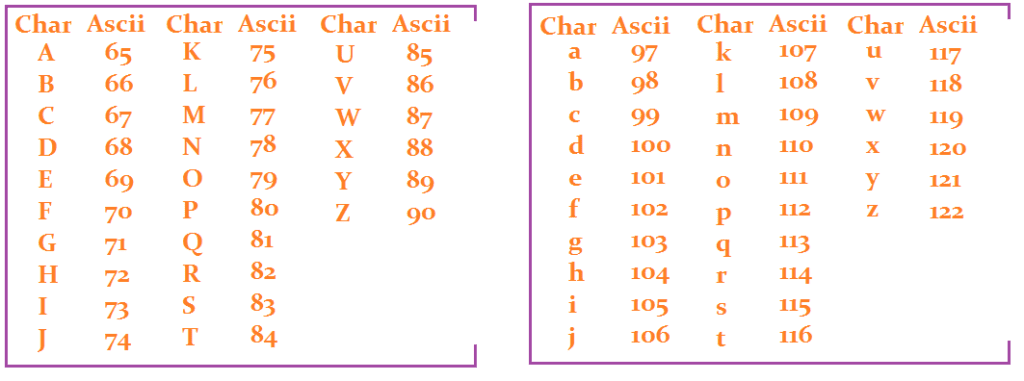
При работе с Unicode в Python мы используем два метода: ord() и chr().
ord(): эта функция принимает символы (буквы на любом языке) и возвращает их уникальный номер по стандарту Unicode.chr(): эта функция принимает целые числа и возвращает их символьный эквивалент по стандарту Unicode.
Примеры работы функций ord() и chr():
print(ord('A')) # 65
print(ord('Z')) # 90
print(ord('F')) # 70
print(chr(65)) # A
print(chr(90)) # Z
print(chr(70)) # F
Теперь, когда вы знаете, что такое Unicode и как получить коды символов и символы, соответствующие кодам Unicode, давайте погрузимся в работу.
Сначала создаем переменную, которая будет хранить строку с заглавными буквами. Затем создаем переменную, которая сначала будет хранить пустую строку, а потом строчные буквы.
word = str(input("Enter a word: " ))
lowercase_letters = ''
Затем мы перебираем все символы строки в цикле:
for char in word:
Как и в прошлом примере, рассмотрим два случая:
- Исходная строка содержит только буквы в верхнем регистре
- Исходная строка может содержать буквы в любом регистре, а также цифры и небуквенные символы
Случай 1. Строка, состоящая исключительно из заглавных букв
Прежде чем преобразовывать прописные буквы в строчные, необходимо проверить, является ли каждый символ строки прописным.
Согласно таблице Unicode, заглавная буква A имеет код 65, а заглавная буква Z – 90. Мы проверяем, входит ли код каждого символа word в диапазон 65-90. Если да, то это прописные буквы.
Функция ord() возвращает уникальный код каждой буквы. Чтобы преобразовать прописные буквы в строчные, мы добавляем к коду каждой прописной буквы разницу между кодами прописных и строчных букв (32). Так мы получаем коды соответствующих строчных букв.
Например:
number_for_A = ord('A')
number_for_a = ord('a')
difference_a = number_for_a - number_for_A
print("Differences in letters", difference_a)
print("The unique number for A", number_for_A)
print("The unique number for a", number_for_a)
# Результат:
# The unique number for A 65
# The unique number for a 97
# Differences in letters 32
number_for_F = ord('F')
number_for_f = ord('f')
difference_f = number_for_f - number_for_F
print("The unique number for F", number_for_F)
print("The unique number for f", number_for_f)
print("Differences in letters", difference_f)
# Результат:
# The unique number for F 70
# The unique number for f 102
# Differences in letters 32
В приведенном выше коде символ “a” имеет код 97 в таблице Unicode, а символ “A” – 65. Разница между ними составляет 32. Чтобы получить значение “a”, нужно прибавить 32 к значению 65.
Таким образом, чтобы найти код строчной буквы, мы должны прибавить 32 к коду прописной:
word = str(input("Enter a word: "))
lowercase_letters = ''
for char in word:
if ord(char) >= 65 and ord(char) <= 90:
char = ord(char) + 32
print(char)
Результат:
Enter a word: REAL 114 101 97 108
В приведенном выше коде мы перебираем в цикле строку, чтобы получить доступ к каждому символу. Мы проверяем код каждого символа: попадает ли он в диапазон 65-90. Если да, то это заглавная буква. Чтобы получить код соответствующей строчной буквы, мы прибавляем 32 к коду заглавной.
Сопоставить числовые коды с буквами можно с помощью функции chr().
word = str(input("Enter a word: "))
lowercase_letters = ''
for char in word:
if ord(char) >= 65 and ord(char) <= 90:
char = ord(char) + 32
to_letters = chr(char)
print(to_letters)
Результат:
Enter a word: REAL r e a l
Мы видим, что возвращаемые буквы являются строчными. Чтобы получить буквы в одной строке, мы добавляем их к переменной, хранящей пустую строку, и выводим ее вне цикла.
word = str(input("Enter a word: "))
lowercase_letters = ''
for char in word:
if ord(char) >= 65 and ord(char) <= 90:
char = ord(char) + 32
to_letters = chr(char)
lowercase_letters += to_letters
print(lowercase_letters)
# Результат:
# Enter a word: FERE
# fere
Вот как это выглядит в виде функции:
def change_to_lowercase(word):
lowercase_letters = ''
for char in word:
if ord(char) >= 65 and ord(char) <= 90:
char = ord(char) + 32
to_letters = chr(char)
lowercase_letters += to_letters
return lowercase_letters
word = str(input("Enter a word: "))
print(change_to_lowercase(word=word))
# Результаты:
# Enter a word: HARDWORKPAYS
# hardworkpays
# Enter a word: PYTHONISFUN
# pythonisfun
Случай 2: строка с буквами в обоих регистрах, а также со специальными символами и цифрами
Для строк, в которых есть небуквенные символы и строчные буквы, мы добавляем оператор else. Все символы, кроме прописных букв, добавляются в lowercase_letters в исходном виде. А прописные буквы преобразуются в строчные:
word = str(input("Enter a word: "))
lowercase_letters = ''
for char in word:
if ord(char) >= 65 and ord(char) <= 90:
char = ord(char) + 32
to_letters = chr(char)
lowercase_letters += to_letters
else:
lowercase_letters += char
print(lowercase_letters)
# Result
# Enter a word: @#&YEAERS09=
# @#&yeaers09=
Вот как это выглядит в виде функции:
def change_to_lowercase(word):
lowercase_letters = ''
for char in word:
if ord(char) >= 65 and ord(char) <= 90:
char = ord(char) + 32
to_letters = chr(char)
lowercase_letters += to_letters
else:
lowercase_letters += char
return lowercase_letters
word = str(input("Enter a word: "))
print(change_to_lowercase(word=word))
# Enter a word: YOUGOT#$^
# yougot#$
# Enter a word: BuLLettrAIn@2022
# bullettrain@2022
Я знаю, что второй метод занимает много времени, но он дает такой же результат, как и первый.
Заключение
В этой статье мы разобрали, как преобразовать строку в нижний регистр. Это можно сделать при помощи встроенного метода Python .lower(), а можно и в цикле. При этом в цикле можно сверять буквы со специально созданным списком букв, а можно воспользоваться встроенными функциями ord() и chr().
Спасибо за внимание!
Перевод статьи Tantoluwa Heritage Alabi “Python lower() – How to Lowercase a Python String with the tolower Function Equivalent”.
Пингбэк: Замена символов в строке в Python - pythonturbo