

Прежде чем перейти к содержанию этой статьи, я хотел бы поделиться причиной, которая побудила меня написать ее.
Я пишу эту статью, потому что вспоминаю, как впервые узнал о сегментации или кластеризации клиентов. Тогда я еще не до конца понимал, что делаю.
Я просто закинул все признаки в KMeans и вот, пожалуйста, – я разработал сегментацию клиентов. Я не понимал атрибутов модели для каждого сегмента.
Поэтому я делюсь своими знаниями о сегментации клиентов и надеюсь, что вы извлечете из этого пользу.
В этом руководстве вы узнаете, как построить эффективную сегментацию клиентов, а также как провести эффективный эксплораторный анализ данных (EDA). Без лишних слов давайте начнем.
Что такое сегментация клиентов?
Мы говорим о сегментации клиентов с самого начала статьи – но вы можете не знать, что это значит.
Обратите внимание, что важно попытаться понять эту теоретическую часть, прежде чем мы перейдем к части статьи, посвященной коду. Этот фундамент поможет вам построить модель эффективно.
Итак, вернемся к определению:
Сегментация означает группировку объектов вместе на основе схожих свойств. Объектами могут быть клиенты, продукты и так далее.
Например, сегментация клиентов, в частности, означает объединение клиентов в группы на основе схожих характеристик или свойств.
При группировке клиентов на основе свойств следует обратить внимание на одну вещь: свойства, которые вы выбираете для группировки клиентов, должны соответствовать критериям, на основе которых вы хотите их сгруппировать.
Например, предположим, вы хотите распределить клиентов по категориям в зависимости от того, что они покупают. В этом сценарии атрибут пола клиента может быть неоптимальным или неактуальным для сегментации.
Знание того, как выбрать подходящие атрибуты для сегментации клиентов, имеет решающее значение.
Давайте рассмотрим различные типы сегментации клиентов:
- Демографическое сегментирование.
- Поведенческая сегментация.
- Географическое сегментирование.
- Психографическая сегментация.
- Технографическая сегментация.
- Сегментация на основе потребностей.
- Сегментация на основе ценностей.
Наиболее частыми типами сегментации потребителей, с которыми вы будете работать при проведении сегментации, являются демографическая и поведенческая сегментации.
Демографическая сегментация – это процесс группировки потребителей на основе их демографии, то есть их возраста, дохода, образования, семейного положения и так далее.
Поведенческая сегментация означает группировку клиентов на основе их поведения. Например, как часто они совершают покупки, общую сумму, которую они тратят на товар, когда они последний раз покупали товар и так далее.
Чтобы узнать больше о других типах сегментации клиентов, вы можете прочитать эту статью.
Критерии для сегментации клиентов
При группировке клиентов следует выбирать релевантные признаки. Но в некоторых случаях имеет смысл объединить признаки из нескольких типов сегментации клиентов для создания другого типа сегментации.
Например, вы можете объединить признаки из демографической и поведенческой сегментации для создания нового типа. Именно этому вы и научитесь в этой статье – мы построим сегментацию клиентов, используя демографические и поведенческие признаки.
Теперь хватит разговоров – давайте перейдем к делу.
Понимание проблемы бизнеса
Бизнес-задача состоит в том, чтобы сегментировать клиентов на основе их личностных качеств(демографическая сегментация) и суммы, которую они тратят на товары (поведенческая сегментация). Это поможет компании лучше понять личные качества и привычки своих клиентов.
Инструменты, которые мы будем использовать для этого проекта
Конечно, мы используем Python для создания нашего проекта – но кроме того вот инструменты и библиотеки, которые мы также будем использовать.
- Среда Jupyter (Jupyter Lab или Jupyter notebook) – для экспериментов с нашим проектом.
- Pandas – для загрузки данных в виде датафрейма и работы с ними.
- Numpy и Scipy – для выполнения некоторых базовых математических вычислений.
- Scikit-Learn – для построения нашей модели сегментации клиентов.
- Seaborn, Matplotlib и Plotly Express – для визуализации данных.
Если у вас нет какой-либо из этих библиотек, вы можете ознакомиться с их официальной документацией в Интернете, чтобы узнать, как их установить.
Набор данных, который мы будем использовать для этого проекта
Набор данных, который мы будем использовать в этом проекте, получен от Kaggle. Вы можете перейти сюда, чтобы загрузить его.
Вот немного информации о наборе данных:
Набор содержит демографические данные клиентов и их поведение по отношению к компании. Характеристики набора данных следующие:

Особенности анализа личности клиента
| PEOPLE | PROMOTION | PRODUCT | PLACE |
|---|---|---|---|
| Year Birth | NumberDealPurchase | MntWines | NumWebPurchases |
| Title | AcceptedCmp1 | MntFruits | NumCatalogPurchases |
| Education | AcceptedCmp2 | MntMeatProducts | NumStorePurchases |
| Marital_Status | AcceptedCmp3 | MntFishProducts | NumWebVisitsMonth |
| Income | AcceptedCmp4 | MntSweetProducts | |
| Kidhome | AcceptedCmp5 | MntGoldProds | |
| Teenhome | Response | ||
| Dt_customer, Recency, | |||
| and Complain |
Чтобы получить максимальную пользу от этого руководства, вы можете предварительно загрузить весь блокнот Jupyter. Вы можете перейти сюда, чтобы сохранить копию репозитория.
Эксплораторный анализ данных (EDA)
Как вы, возможно, знаете, EDA – это ключ к успешной работе в качестве аналитика данных или специалиста по исследованию данных. Он дает вам информацию из первых рук обо всем наборе данных и помогает понять все взаимосвязи между характеристиками.
В этом учебном пособии мы выполним три этапа EDA, а именно:
- Одномерный анализ.
- Двумерный анализ.
- Многомерный анализ
Для начала нам нужно импортировать все необходимые библиотеки, которые мы будем использовать в этом проекте. Нам также необходимо загрузить набор данных в датафрейм, чтобы мы могли увидеть все характеристики, которые в нем присутствуют.
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import plotly.express as px
import numpy as np
from scipy.stats import iqr
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
df = pd.read_csv("data/marketing_campaign.csv", sep="\t")
df.head()
Начнем с того, что в датафрейме имеется множество характеристик, но поскольку мы хотим сосредоточиться на демографических характеристиках и поведении клиентов, мы будем проводить EDA только для характеристик, относящихся к этим категориям.
Имейте в виду, что EDA, проведенная в этой статье, является лишь подмножеством той, что описана в Jupyter Notebook. Это сделано для того, чтобы статья не стала слишком замороченной. Чтобы найти весь EDA в блокноте, откройте репозиторий по этой ссылке.
Возраст, доход, семейное положение, образование, общее количество детей и сумма, потраченная на продукты, – вот атрибуты, которые относятся к интересующей нас категории.
Во-первых, поскольку сегментация основана на общей сумме, потраченной клиентами, мы сложим траты на отдельные продукты:
df["TotalAmountSpent"] = df["MntFishProducts"] + df["MntFruits"] + df["MntGoldProds"] + df["MntSweetProducts"] + df["MntMeatProducts"] + df["MntWines"]
После этого мы можем приступить. Эффективный EDA всегда состоит из трех этапов, как я уже упоминал выше. Они, повторюсь, следующие:
- Одномерный анализ
- Двумерный анализ.
- Многомерный анализ.
Одномерный анализ
Одномерный анализ подразумевает оценку одного признака с целью получения информации о нем. Таким образом, начальным шагом при выполнении EDA является проведение одномерного анализа, который включает в себя оценку описательной или сводной статистики о признаке.
Например, можно проверить распределение признака, долю признака и так далее.
В нашем случае мы проверим распределение возраста клиентов в датафрейме. Мы можем сделать это, набрав следующее:
sns.histplot(data=df, x="Age", bins = list(range(10, 150, 10)))
plt.title("Distribution of Customer's Age")
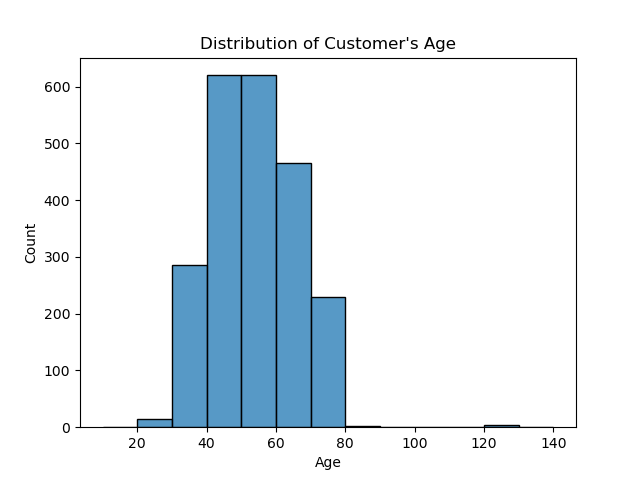
Из приведенной выше сводки видно, что большинство клиентов относятся к возрастному диапазону 40-60 лет.
Двумерный анализ
После того как вы провели одномерный анализ всех интересующих вас признаков, следующим шагом будет проведение двумерного анализа. Это предполагает одновременное сравнение двух признаков.
Двумерный анализ используется, например, для определения корреляции между двумя признаками.
В нашем случае некоторые из двумерных анализов, которые мы будем проводить в рамках проекта, включают наблюдение за средней суммой потраченных средств в различных возрастных группах клиентов, определение корреляции между доходом клиента и общей суммой потраченных средств и так далее, как показано ниже.
Например, в нашем случае мы хотим проверить взаимосвязь между Income клиента и TotalAmountSpent. Мы можем сделать это посредством следующего кода:
fig = px.scatter(data_frame=df_cut, x="Income",
y="TotalAmountSpent",
title="Relationship Between Customer's Income and Total Amount Spent",
height=500,
color_discrete_sequence = px.colors.qualitative.G10[1:])
fig.show()
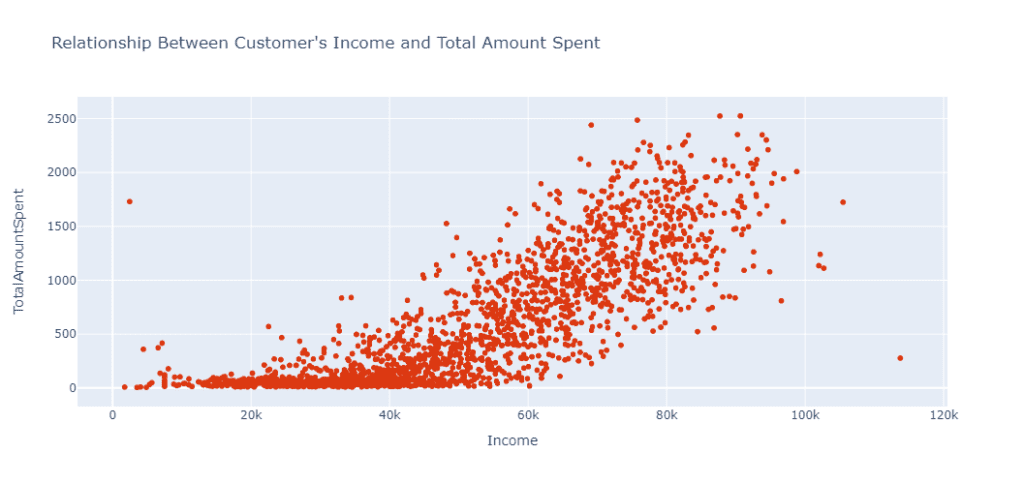
Из приведенного выше анализа видно, что с увеличением Income увеличивается и TotalAmountSpent. Таким образом, из анализа мы можем сделать вывод, что Income является одним из ключевых факторов, определяющих, сколько клиент может потратить.
Многомерный анализ
После завершения одномерного и двумерного анализа, последним этапом EDA является выполнение многомерного анализа.
Многомерный анализ заключается в установлении взаимосвязи между двумя или более переменными.
В нашем проекте одним из видов многомерного анализа будет анализ взаимосвязи между Income, TotalAmountSpent и Education клиента.
fig = px.scatter(
data_frame=df_cut,
x = "Income",
y= "TotalAmountSpent",
title = "Relationship between Income VS Total Amount Spent Based on Education",
color = "Education",
height=500
)
fig.show()
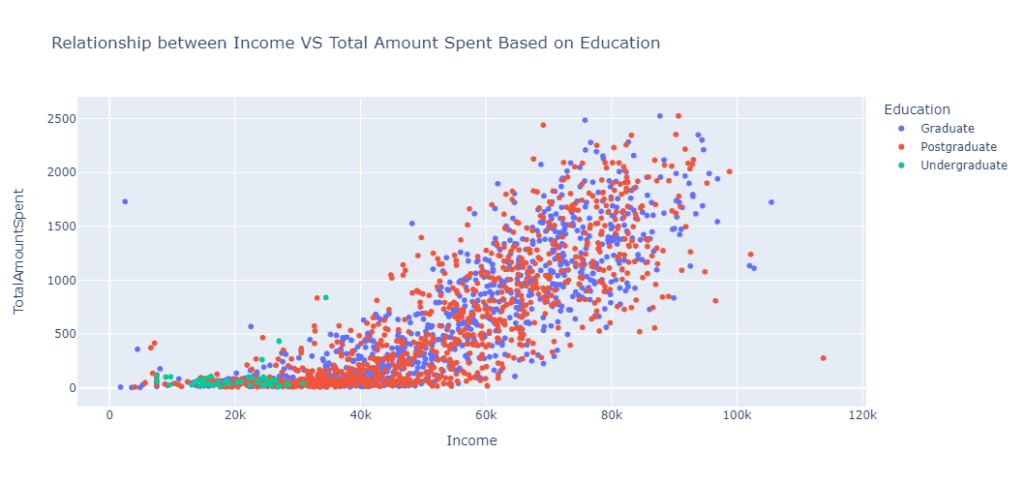
Из анализа видно, что клиенты с уровнем образования ниже среднего обычно тратят меньше, чем другие клиенты с более высоким уровнем образования. Это объясняется тем, что клиенты с уровнем образования ниже среднего обычно зарабатывают меньше, чем другие, что влияет на их привычки в отношении расходов.
Как построить модель сегментации
После завершения анализа следующим шагом будет создание модели, которая позволит сегментировать клиентов. Мы будем использовать модель KMeans. Это популярная модель сегментации, которая является достаточно эффективной.
Модель KMeans – это модель машинного обучения без надзора, которая работает путем простого разбиения N наблюдений на K кластеров. Наблюдения группируются в эти кластеры на основе того, насколько близко они находятся к среднему значению данного кластера, которое обычно называют центроидом.
Когда вы подгоните признаки к модели и укажете количество кластеров или сегментов, KMeans выведет метку кластера, к которому принадлежит каждое наблюдение в признаке.
Давайте поговорим о признаках, которые вы, возможно, захотите вписать в модель KMeans. Количество признаков, которые вы можете использовать для построения модели сегментации клиентов, не ограничено, но, на мой взгляд, чем меньше, тем лучше . Это связано с тем, что с меньшим количеством признаков вы сможете легче понять и интерпретировать результаты каждого сегмента.
В нашем сценарии мы сначала построим первую модель KMeans с двумя признаками, а затем окончательную, с тремя. Но прежде чем мы начнем, давайте пройдемся по требованиям KMeans, которые заключаются в следующем:
- Признаки должны быть числовыми.
- Признаки, которые вы вводите в KMeans, должны быть нормально распределены. Это связано с тем, что KMeans (поскольку он вычисляет среднее значение) подвержен влиянию выбросов (значений, которые сильно отклоняются от других). Поэтому любая такая характеристика должна быть изменена, чтобы стать нормально распределенной. К счастью, мы можем использовать пакет преобразования логарифмов Numpy np.log().
- Характеристики также должны иметь одинаковый масштаб. Для этого мы воспользуемся модулем Scikit-learn StandardScaler().
Теперь, когда мы поняли основную концепцию, мы разработаем нашу первую модель KMeans. Для нее мы будем использовать характеристики Income и TotalAmountSpent.
Для начала, поскольку функция Income имеет недостающие значения, мы заполним ее медианным числом.
data = df[[“Income”, “TotalAmountSpent”]]
После этого мы преобразуем функции и сохраним результат в переменной под названием data_log.
df_log = np.log(data)
Затем мы масштабируем результат с помощью Scikit-learn StandardScaler():
std_scaler = StandardScaler() df_scaled = std_scaler.fit_transform(df_log)
После этого мы можем построить модель. Итак, модель KMeans требует двух параметров. Первый – random_state, а второй – n_clusterswhere:
- n_clusters представляет собой количество кластеров или сегментов, которые будут получены из KMeans.
- random_state: требуется для воспроизводимых результатов.
В деловой среде вы можете заранее знать количество кластеров, на которые вы хотите сегментировать клиентов. Но если нет, вам придется поэкспериментировать с различными количествами кластеров, чтобы найти оптимальное.
Поскольку у нас не бизнес-среда, этим мы и займемся.
Метод локтя – это стратегия, которую мы будем использовать для выбора лучшего кластера. Он работает просто: строится график ошибок каждого кластера и ищется место, которое образует локоть на графике. В результате идеальным кластером будет тот, который образует этот локоть.
Вот код, который поможет нам в этом:
errors = []
for k in range(1, 11):
model = KMeans(n_clusters=k, random_state=42)
model.fit(df_scaled)
error.append(model.inertia_)
plt.title('The Elbow Method')
plt.xlabel('k'); plt.ylabel('Error of Cluster')
sns.pointplot(x=list(range(1, 11), y=errors)
plt.show()
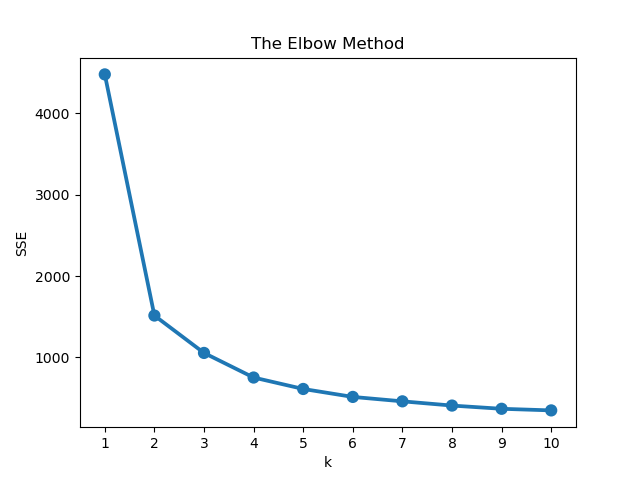
Давайте разберем, что делает приведенный выше код. Мы задали количество кластеров для эксперимента, которое находится в диапазоне (1, 11). Затем мы подогнали к ним признаки и добавили ошибку в список, который мы создали выше.
После этого мы построили график ошибки для каждого кластера. На диаграмме видно, что кластер, который создает локоть – третий. Таким образом, три кластера – это наилучшее значение для построения нашей модели KMeans.
model = KMeans(n_clusters = 3, random_state=42) model.fit(df_scaled)
Теперь, когда мы построили нашу модель, следующим шагом будет присвоение метки кластера для каждого наблюдения. Поэтому мы присвоим метку исходному признаку, который мы не обрабатывали. Там, где мы присвоили , Income и TotalAmountSpent переменной data
data = data.assign(ClusterLabel = model.labels_)
Как интерпретировать результат кластера
Теперь, когда мы построили модель, следующим шагом будет интерпретация результатов каждого кластера.
Существует множество способов обобщения результатов кластера в зависимости от того, чего вы хотите добиться. Наиболее распространенным способом обобщения является использование центральной тенденции, которая включает в себя среднее значение, медиану и моду.
В нашем случае мы будем использовать медиану, потому что в исходных характеристиках есть выбросы, а среднее значение очень чувствительно к выбросам.
Поэтому мы объединим метки кластеров и найдем медиану для Income и TotalAmountSpent. Для этого мы можем использовать метод Pandas groupby.
data.groupby(“ClusterLabel”)[[“Income”, “TotalAmountSpent”]].median()

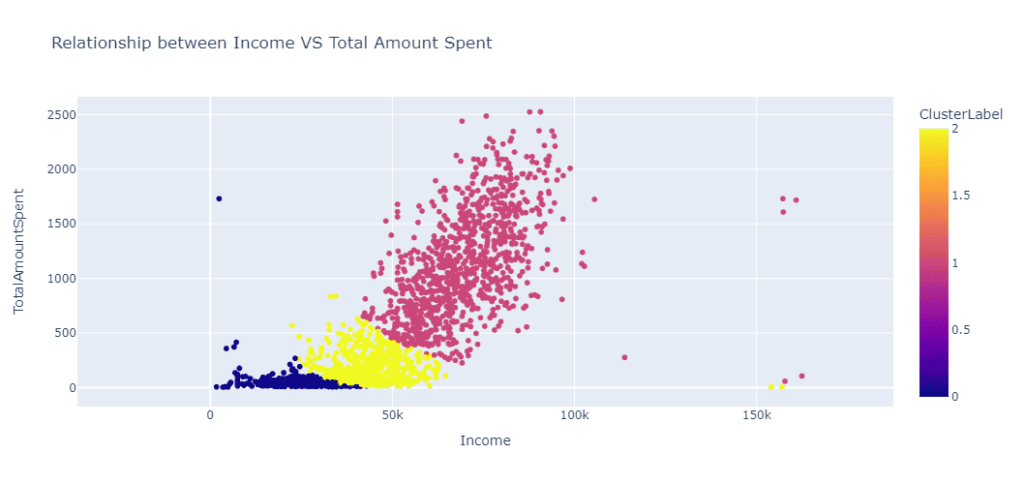
Мы видим, что внутри кластеров существует тенденция:
- Кластер 0 означает клиентов, которые мало зарабатывают и мало тратят .
- Кластер 1 представляет клиентов, которые зарабатывают много и много тратят.
- Кластер 2 представляет клиентов, которые зарабатывают и тратят умеренно.
Мы также можем визуализировать эту взаимосвязь, с помощью следующего кода:
fig = px.scatter(
data_frame=data,
x = "Income",
y= "TotalAmountSpent",
title = "Relationship between Income VS Total Amount Spent",
color = "ClusterLabel",
height=500
)
fig.show()
Теперь таким же образом, как мы строили формальную модель, мы построим модель KMeans, используя 3 признака (метод локтя также показывает, что 3 кластера являются оптимальным выбором).
data = df[["Age", "Income", "TotalAmountSpent"]] df_log = np.log(data) std_scaler = StandardScaler() df_scaled = std_scaler.fit_transform(df_log)
model = KMeans(n_clusters=3, random_state=42)
model.fit(df_scaled)
data = data.assign(ClusterLabel= model.labels_)
result = df_result.groupby("ClusterLabel").agg({"Age":"mean", "Income":"median", "TotalAmountSpent":"median"}).round()
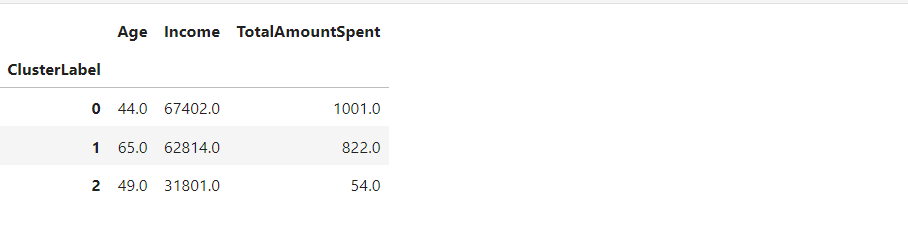
Из приведенных выше данных, становится ясно, что:
- Кластер 0 обозначает молодых клиентов, которые много зарабатывают и много тратят.
- Кластер 1 означает пожилых клиентов, которые много зарабатывают и много тратят.
- Кластер 2 представляет молодых клиентов, которые зарабатывают мало и мало тратят.
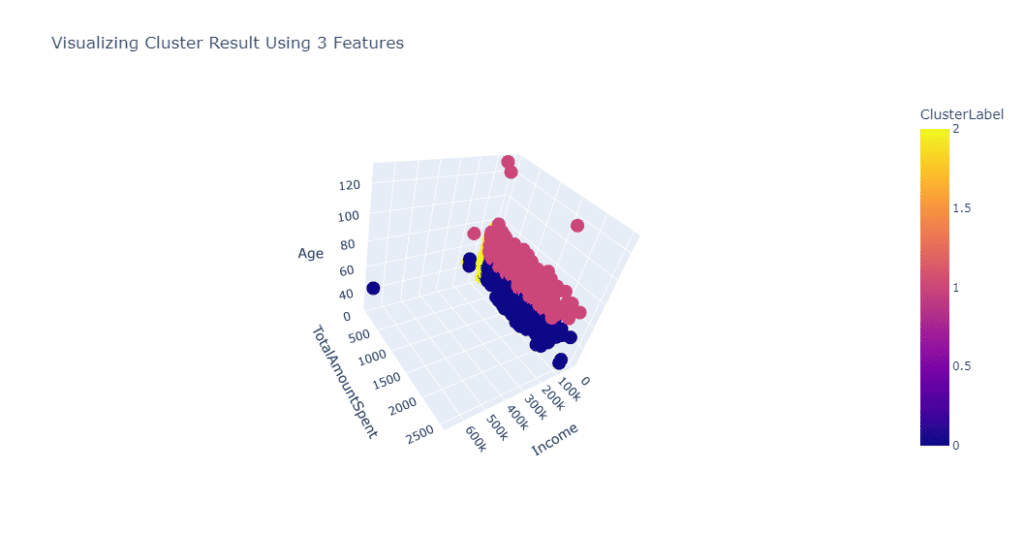
Мы также можем визуализировать наш результат с помощью следующего кода:
fig = px.scatter_3d(data_frame=data, x="Income",
y="TotalAmountSpent", z="Age", color="ClusterLabel", height=550,
title = "Visualizing Cluster Result Using 3 Features")
fig.show()
Заключение
В этом руководстве вы узнали, как построить модель сегментации клиентов. Однако, существует еще множество функций, которые мы не затронули в этой статье. Я предлагаю вам поэкспериментировать и создать свои модели сегментации клиентов.
Надеюсь, вы узнали много нового. Спасибо, что прочитали статью. Удачного кодинга!
Ссылка на скрипт. А вот статья о кластеризации K-Means, если вы хотите узнать больше.
Перевод статьи Ibrahim Abayomi Ogunbiyi «How to Perform Customer Segmentation in Python – Machine Learning Tutorial».