
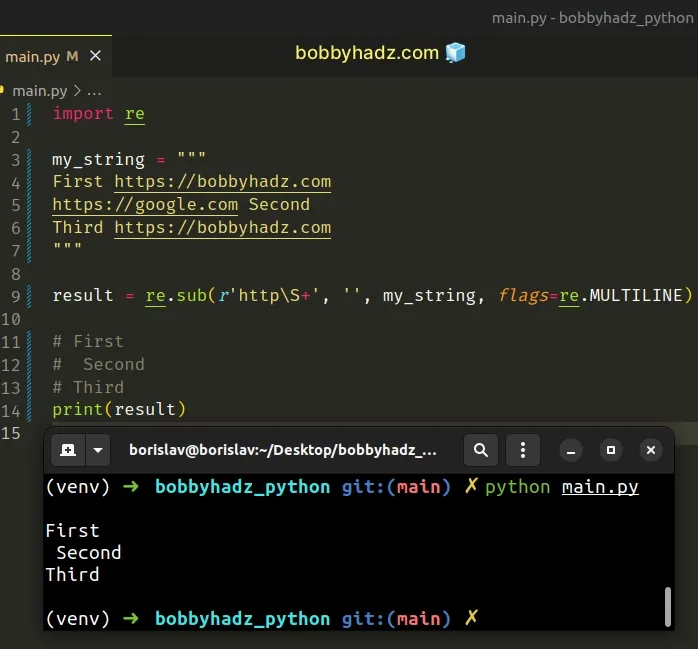
Чтобы удалить URL из текста, используйте метод re.sub(). Он удалит все URL из строки, заменив их пустыми строками.
import re my_string = """ First https://bobbyhadz.com https://google.com Second Third https://bobbyhadz.com """ result = re.sub(r'http\S+', '', my_string, flags=re.MULTILINE) # First # Second # Third print(result)
Метод re.sub() возвращает новую строку, полученную путем замены всех вхождений шаблона на указанную строку.
import re my_str = '1apple, 2apple, 3banana' result = re.sub(r'[0-9]', '_', my_str) print(result) # 👉️ _apple, _apple, _banana
Если шаблон не найден, строка возвращается как есть.
Мы использовали пустую строку для замены, потому что хотим удалить все URL из строки.
import re my_string = """ First https://bobbyhadz.com https://google.com Second Third https://bobbyhadz.com """ result = re.sub(r'http\S+', '', my_string, flags=re.MULTILINE) # First # Second # Third print(result)
Первый аргумент, который мы передали методу re.sub(), – это регулярное выражение.
Символы http в регулярном выражении – те символы, на которые мы опираемся при поиске URL.
\S соответствует любому непробельному символу. Обратите внимание, что S – заглавная.
Плюс + означает, что предыдущий символ может встречаться один или более раз. В нашем случае «предыдущий» – это любой непробельный символ.
В целом регулярное выражение соответствует подстрокам, начинающимся с последовательности символов http, за которой следует один или более символов, не являющихся пробельными.
Более конкретное регулярное выражение для поиска URL
Если вы беспокоитесь, что с шаблоном совпадут строки типа http-something, измените регулярное выражение на r'https?://\S+'.
import re my_string = """ First https://bobbyhadz.com https://google.com Second Third https://bobbyhadz.com """ result = re.sub(r'https?://\S+', '', my_string) # First # Second # Third print(result)
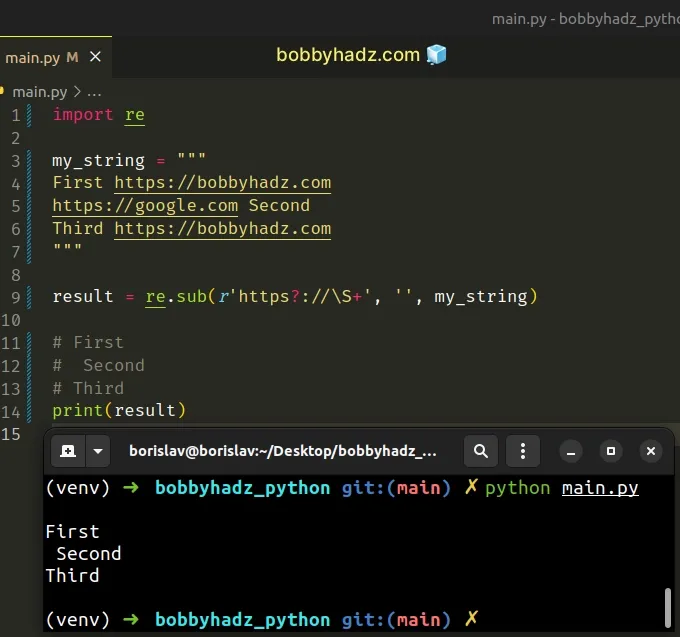
Вопросительный знак ? означает 0 или 1 вхождение предшествующего символа. Например, https? будет соответствовать либо https, либо http.
Далее идут двоеточие и две прямые косые черты :// для завершения протокола.
В целом регулярное выражение соответствует подстрокам, начинающимся с http:// или https://, за которыми следует один или более непробельных символов.
Если вам понадобится помощь в чтении или написании регулярного выражения, обратитесь к подразделу “Синтаксис регулярных выражений” в официальной документации. На этой странице вы найдете список всех специальных символов и множество полезных примеров.
Удаление URL-адресов из текста с помощью re.findall()
Для удаления URL-адресов из строки также можно использовать метод re.findall().
import re
my_string = """
First https://bobbyhadz.com
https://google.com Second
Third https://bobbyhadz.com
"""
new_string = my_string
matches = re.findall(r'http\S+', my_string)
print(matches)
for match in matches:
new_string = new_string.replace(match, '')
# First
# Second
# Third
print(new_string)
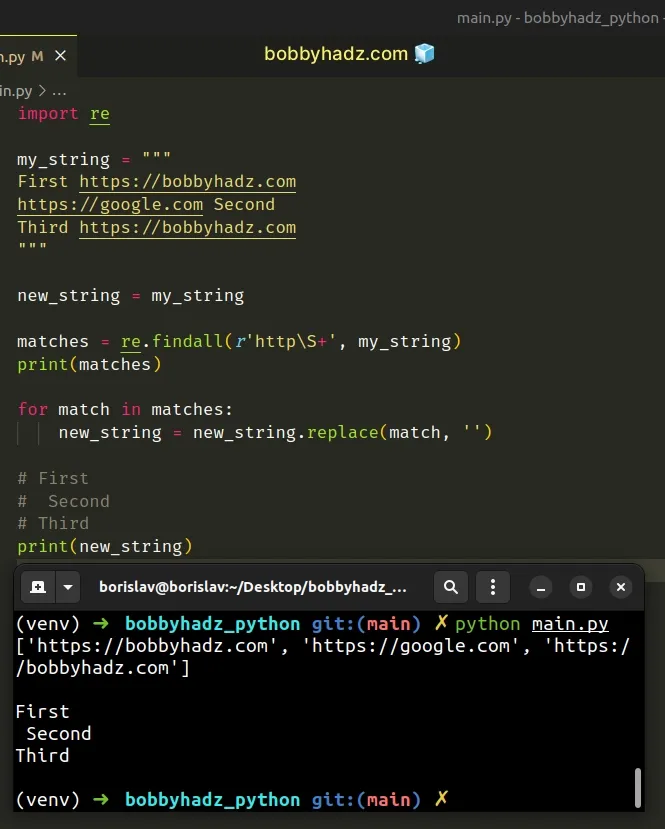
Метод re.findall принимает в качестве аргументов шаблон и строку и возвращает список строк, содержащий все неперекрывающиеся совпадения шаблона в строке.
Мы использовали цикл for для итерации по списку совпадений.
На каждой итерации мы используем метод str.replace для удаления текущего совпадения из URL.
Вы можете использовать этот подход, если хотите сохранить некоторые URL в тексте на основе условия.
Вот пример:
import re
my_string = """
First https://bobbyhadz.com
https://google.com Second
Third https://bobbyhadz.com
"""
new_string = my_string
matches = re.findall(r'http\S+', my_string)
print(matches)
for match in matches:
if 'google' not in match:
new_string = new_string.replace(match, '')
# First
# https://google.com Second
# Third
print(new_string)
На каждой итерации цикла for мы проверяем, что текущее совпадение не содержит строку google. Если условие выполняется, URL удаляется.
Перевод статьи «How to Remove URLs from Text in Python».